AI答应用平台笔记
MBTI性格测试小程序
需求分析

系统架构
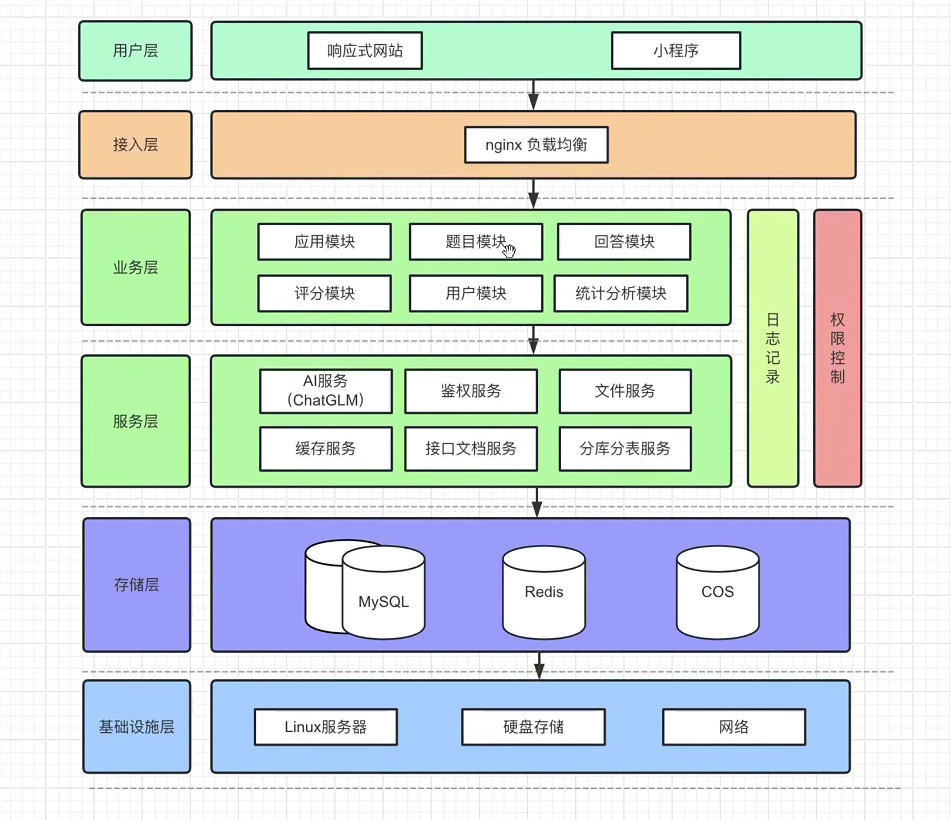
开源大模型 chatglm,可本地部署
MBTI实现方案
题目

答案

答案表
技术选型
Taro跨平台多端编译
官网文档:https://taro-docs.jd.com/docs/
组件库,最好使用官方自带的组件库,否则会出现跨端样式丢失的问题
taro-ui:https://taro-ui.jd.com/#/
安装
# 使用 npm 安装 CLI
$ npm install -g @tarojs/cli
运行和查看运行效果
# 运行
npm run dev:weapp
查看效果要在微信开发者工具上(一定要升级到最新版!!!不升级运行不了!!!)
导入项目,生成APPID测试号,编译完就可以看到效果了
配置文件
project.config.json
顾名思义:项目配置,小程序开发工具识别的配置参数
app.config.ts
程序配置:可以配置整个程序的颜色,标题等信息
小程序发布
执行build命令打包代码
删除dist目录,清理开发者工具缓存,执行build:weapp,再次运行,验证效果
小程序网络请求
请求库
小程序环境无法直接使用Axios
小程序适配器库:https://github.com/bigmeow/taro-platform/tree/master/packages/axios-taro-adapter
请求代码生成
根据后端OpenAPI规范的接口文档(比如Swagger自动生成)
推荐:https://www.npmjs.com/package/@umijs/openapi
全局请求处理器
自己定义请求的全局参数、增加全局请求处理器、响应处理器
参考:https://axios-http.com/docs/instance
小程序状态管理
多个页面的共享变量,当变量变化可以触发界面更新
简易版:创建一个全局的JS变量,或者利用小程序的(Storage)共享变量
主流:Redux的工具库
https://react-redux.js.org/tutorials/quick-start
更新全局状态
store.dispatch(setLoginUser(loginUser));
获取全局状态
const loginUser = useSelector((state: any) => state.loginUser)
小程序用户登录
小程序提供了登录接口
https://docs.taro.zone/docs/apis/open-api/login/
// 完整代码
import { Component, PropsWithChildren } from 'react'
import Taro from '@tarojs/taro' // 引入 Taro
import 'taro-ui/dist/style/index.scss' // 引入组件样式 - 方式一
import './app.scss'
class App extends Component<PropsWithChildren> {
componentDidMount() {
this.handleLogin()
}
componentDidShow() {}
componentDidHide() {}
// 获取用户登录信息
handleLogin = async () => {
try {
const loginResult = await Taro.login()
if (loginResult.code) {
// 成功获取登录 code,通常需要发送到服务器以换取用户信息
console.log('登录 code:', loginResult.code)
// TODO: 将 code 发送到服务器
} else {
console.error('登录失败!', loginResult.errMsg)
}
} catch (error) {
console.error('调用 Taro.login 失败!', error)
}
}
render() {
return this.props.children
}
}
export default App
看着代码多,实际上就是在页面挂载的钩子里调用Taro.login(),返回的数据有code,把这个返回给后端处理
后端可以使用WxJava库
如何保证小程序全局自动登录
1、首次登录app,在app.ts中触发自动登录
2、每次操作出现未登录,立即调用登录函数
怎么存储session和携带cookie信息
// 请求拦截器
const requestInterceptor = (config: InternalAxiosRequestConfig) => {
config.headers.cookie = Taro.getStorageSync(COOKIE_KEY);
return config;
};
// 响应拦截器
const responseInterceptor = (response: AxiosResponse) => {
// 自动种上 Cookie(和业务逻辑无关,弥补小程序没有 Cookie 管理机制)
const cookie = response.headers["Set-Cookie"];
if (cookie) {
Taro.setStorageSync(COOKIE_KEY, cookie);
}
...
}
后端开发
需求分析
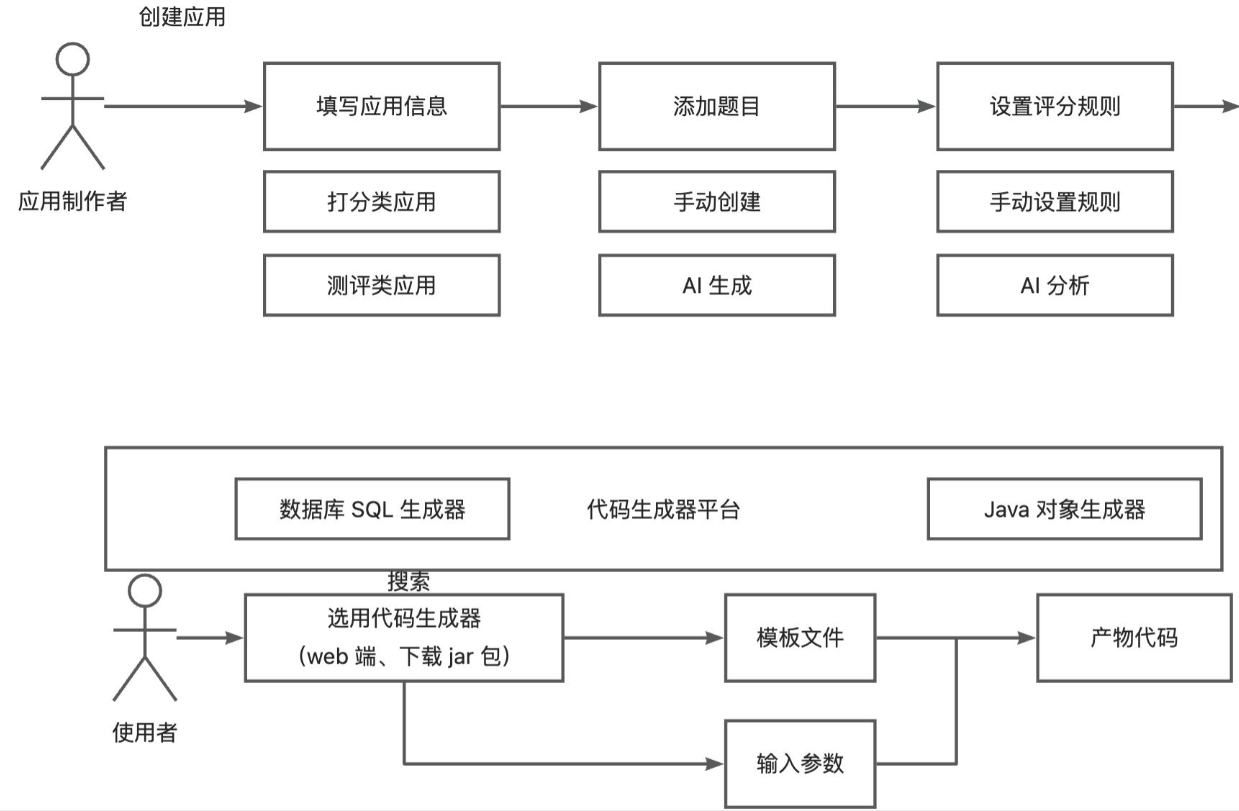
1、用户注册、用户登录
2、用户创建应用- > 创建题目(包括题目选项得分)-> 创建评分规则(评分策略【得分、测评】和评分结果)
3、管理员管理应用,审核发布下架应用
4、用户查看和检索应用列表,进入应用详情页,题目详情页,在线答题并提交
5、经过评分模块计算后,用户可查看本次评分结果
具体需求及优先级
用户模块
注册 0
登录 0
管理用户 - 增删改查(管理员)1
应用模块
创建应用 0
修改应用 1
删除应用 1
查看应用列表 0
查看应用详情 0
查看自己创建的应用 1
管理应用 - 增删改查(管理员)0
审核发布和下架应用(管理员)0
应用分享(扫码查看)2
题目模块
创建题目(包括题目选项得分设置)0
修改题目 1
删除题目 1
管理题目 - 增删改查(管理员)1
AI生成题目 1
评分模块
创建评分结果 0
修改评分结果 1
删除评分结果 1
根据回答计算评分结果
自定义测评类 0
自定打分类 0
AI评分 1
管理评分结果 - 增删改查(管理员) 1
回答模块
提交答案 0
查看某次回答的评分结果 0
查看自己提交的回答列表 1
管理回答 - 增删改查(管理员)1
统计分析模块
应用评分结果分析和查看 2
库表设计
用户表
-- 用户表
create table if not exists user
(
id bigint auto_increment comment 'id' primary key,
userAccount varchar(256) not null comment '账号',
userPassword varchar(512) not null comment '密码',
unionId varchar(256) null comment '微信开放平台id',
mpOpenId varchar(256) null comment '公众号openId',
userName varchar(256) null comment '用户昵称',
userAvatar varchar(1024) null comment '用户头像',
userProfile varchar(512) null comment '用户简介',
userRole varchar(256) default 'user' not null comment '用户角色:user/admin/ban',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_unionId (unionId)
) comment '用户' collate = utf8mb4_unicode_ci;
用户角色:普通用户、管理员、禁用、也可以加会员
应用表
-- 应用表
create table if not exists app
(
id bigint auto_increment comment 'id' primary key,
appName varchar(128) not null comment '应用名',
appDesc varchar(2048) null comment '应用描述',
appIcon varchar(1024) null comment '应用图标',
appType tinyint default 0 not null comment '应用类型(0-得分类,1-测评类)',
scoringStrategy tinyint default 0 not null comment '评分策略(0-自定义,1-AI)',
reviewStatus int default 0 not null comment '审核状态:0-待审核, 1-通过, 2-拒绝',
reviewMessage varchar(512) null comment '审核信息',
reviewerId bigint null comment '审核人 id',
reviewTime datetime null comment '审核时间',
userId bigint not null comment '创建用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_appName (appName)
) comment '应用' collate = utf8mb4_unicode_ci;
审核需要字段
reviewStatus int default 0 not null comment '审核状态:0-待审核, 1-通过, 2-拒绝',
reviewMessage varchar(512) null comment '审核信息',
reviewerId bigint null comment '审核人 id',
reviewTime datetime null comment '审核时间',
题目表
-- 题目表
create table if not exists question
(
id bigint auto_increment comment 'id' primary key,
questionContent text null comment '题目内容(json格式)',
appId bigint not null comment '应用 id',
userId bigint not null comment '创建用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_appId (appId)
) comment '题目' collate = utf8mb4_unicode_ci;
questionContent结构
[
{
"options": [
{
"result": "I", // 如果是测评类,则用 reslut 来保存答案属性
"score": 1, // 如果是得分类,则用 score 来设置本题分数
"value": "A选项", //选项内容
"key": "A" //选项 key
},
{
"result": "E", // 如果是测评类,则用 reslut 来保存答案属性
"score": 0,
"value": "B选项",
"key": "B"
}
],
"title": "题目"
}
]
questionContent为什么设置成json,不单做一张表?
解释:因为问题有很多,问题的顺序可能会变化,这时候还需要order来记录顺序,后期修改题目的时候对数据库的操作比较重,json这种方式比较灵活,增减字段,增加题目,修改题目,操作起来很灵活。
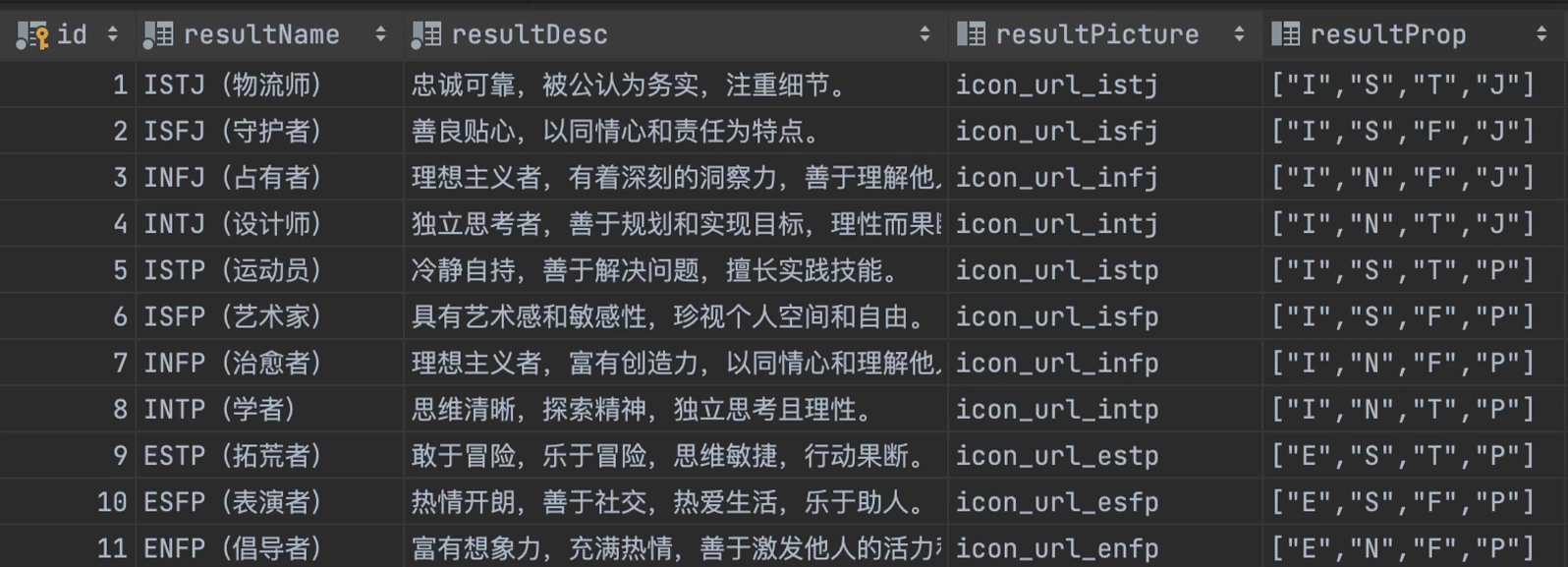
评分结果表
-- 评分结果表
create table if not exists scoring_result
(
id bigint auto_increment comment 'id' primary key,
resultName varchar(128) not null comment '结果名称,如物流师',
resultDesc text null comment '结果描述',
resultPicture varchar(1024) null comment '结果图片',
resultProp varchar(128) null comment '结果属性集合 JSON,如 [I,S,T,J]',
resultScoreRange int null comment '结果得分范围,如 80,表示 80及以上的分数命中此结果',
appId bigint not null comment '应用 id',
userId bigint not null comment '创建用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_appId (appId)
) comment '评分结果' collate = utf8mb4_unicode_ci;
这个表两个字段二选一,resultProp,结果属性集合JSON,这个是测评表的结果。resultScoreRange结果得分范围,这个是得分表的结果。那么为什么用int就能表示范围呢?
解释:90 表示 90以上,80表示80以上,用switch语句,先判断是否>90,是,就不会执行下面的语句。这样90,代表90-100,80代表80-90,就可以用一个数表示一段数据了。
用户答题记录表
-- 用户答题记录表
create table if not exists user_answer
(
id bigint auto_increment primary key,
appId bigint not null comment '应用 id',
appType tinyint default 0 not null comment '应用类型(0-得分类,1-角色测评类)',
scoringStrategy tinyint default 0 not null comment '评分策略(0-自定义,1-AI)',
choices text null comment '用户答案(JSON 数组)',
resultId bigint null comment '评分结果 id',
resultName varchar(128) null comment '结果名称,如物流师',
resultDesc text null comment '结果描述',
resultPicture varchar(1024) null comment '结果图标',
resultScore int null comment '得分',
userId bigint not null comment '用户 id',
createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
isDelete tinyint default 0 not null comment '是否删除',
index idx_appId (appId),
index idx_userId (userId)
) comment '用户答题记录' collate = utf8mb4_unicode_ci;
为什么设计resultId可能为null?
解释:因为我们的结果来源有两种,一是从评分结果表中找到的结果,这肯定是有resultId的。但是第二种,AI分析后生成的结果,这种是没有resultId的,所以resultId很可能为空。
还有个原因,答案没提交,临时保存答案,测评结果这时是没有的。或者提交答案和测评结果是异步的,有时间差,这段时间没有resultId。
评分结果表有resultName,resultDesc,resultPicture等字段,为什么用户答题记录表还要有这些个字段?
解释:因为查询是系统最常用的操作,联表操作leftjoin查询性能比较差,有了这些个常用的冗余字段,就可以省去连表查询了。
choice的结构
["A", "B", "C"]
一般默认答题的顺序是不变的,为了保证答题顺序改变导致结果出现问题,可以用以下结构设计
{
1: "A",
2: "B"
}
代码开发
基础crud开发
用mybatisX自带的代码生成器生成entity、mapper代码,具体配置如下:
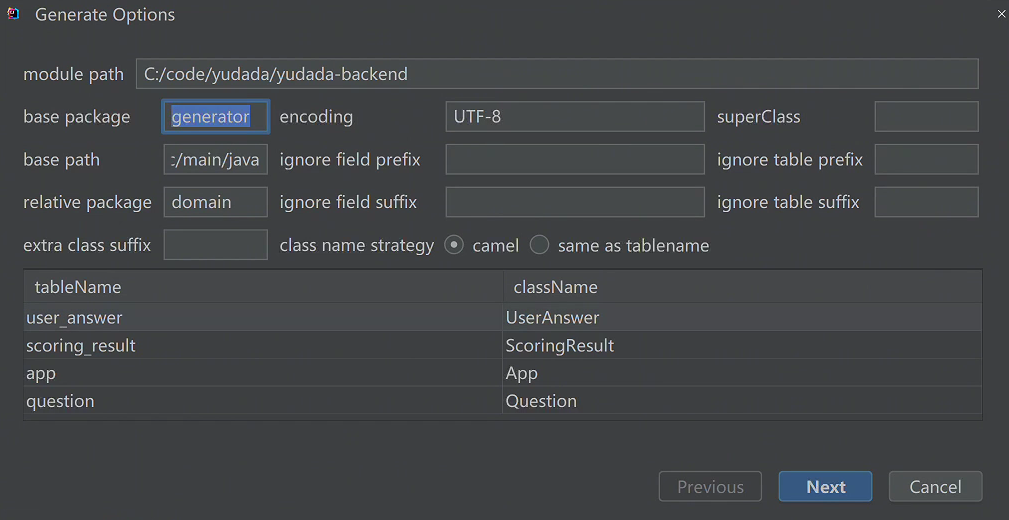
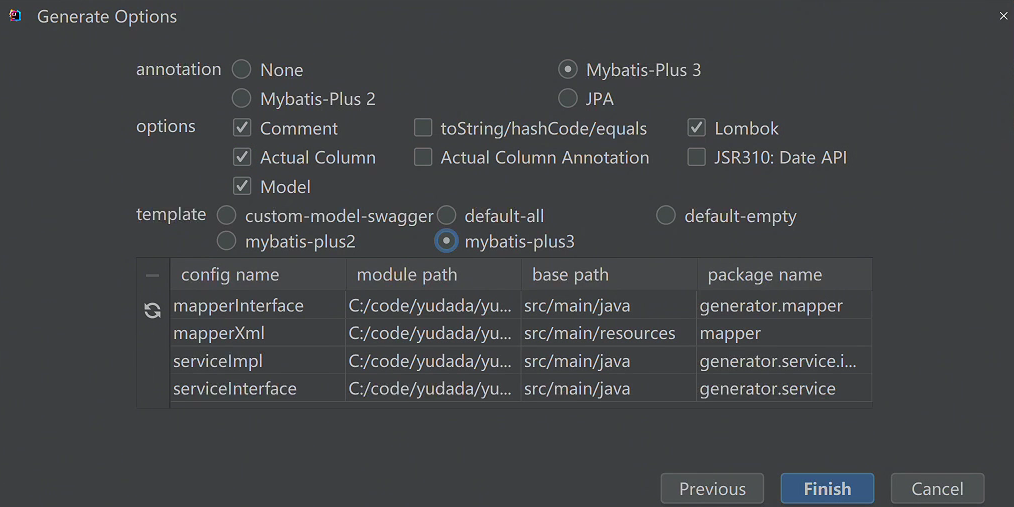
用鱼皮做的代码生成器生成其他代码,配置以下信息,运行generate下的CodeGenetator
核心业务开发
应用模块
审核发布和下架应用(管理员)
评分模块
根据回答计算评分结果
自定义规则评分 - 测评类
自定义评分规则 - 打分类
回答模块
提交回答,调用评分模块更新回答表
评分模块实现
需求:根据不用的应用类别和评分策略,实现不同的评分逻辑
设计模式:策略模式
原因:输入参数一致,实现评分的逻辑不同
评分策略接口
package com.snowyee.yudada.scoring;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.UserAnswer;
import java.util.List;
public interface ScoringStrategy {
/**
* 执行评分
*/
UserAnswer doScore(List<String> choices, App app) throws Exception;
}
测评类评分策略实现类
package com.snowyee.yudada.scoring.impl;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.snowyee.yudada.model.dto.question.QuestionContentDTO;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.Question;
import com.snowyee.yudada.model.entity.ScoringResult;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.model.vo.QuestionVO;
import com.snowyee.yudada.scoring.ScoringStrategy;
import com.snowyee.yudada.scoring.ScoringStrategyConfig;
import com.snowyee.yudada.service.QuestionService;
import com.snowyee.yudada.service.ScoringResultService;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@ScoringStrategyConfig(appType = 1, scoringStrategy = 0)
public class CustomTestScoringStrategyImpl implements ScoringStrategy {
@Resource
private QuestionService questionService;
@Resource
private ScoringResultService scoringResultService;
@Override
public UserAnswer doScore(List<String> choices, App app) throws Exception {
// 1. 根据id查询到题目和题目结果信息
Long appId = app.getId();
Question question = questionService.getOne(
Wrappers.lambdaQuery(Question.class)
.eq(Question::getAppId, appId)
);
List<ScoringResult> scoringResultList = scoringResultService.list(
Wrappers.lambdaQuery(ScoringResult.class)
.eq(ScoringResult::getAppId, appId)
);
// 2. 统计用户每个选项对应的属性个数,如 I = 10 个,E = 5 个
Map<String , Integer> optionCount = new HashMap<>();
QuestionVO questionVO = QuestionVO.objToVo(question);
List<QuestionContentDTO> questionContent = questionVO.getQuestionContent();
for (QuestionContentDTO questionContentDTO : questionContent) {
for (String choice : choices) {
for (QuestionContentDTO.OptionDTO option : questionContentDTO.getOptions()) {
if (option.getKey().equals(choice)) {
String result = option.getResult();
if (!optionCount.containsKey(result)) {
optionCount.put(result, 1);
}
optionCount.put(result, optionCount.get(result) + 1);
}
}
}
}
// 3. 遍历每种评分结果,计算哪个结果的得分更高
int maxScore = 0;
ScoringResult maxScoringResult = scoringResultList.get(0);
for (ScoringResult scoringResult : scoringResultList) {
List<String> resultProp = JSONUtil.toList(scoringResult.getResultProp(), String.class);
// 计算当前评分结果的分数,比如结果是【I,E】,I的个数是10,E的个数是5,那么算出来这个result的分数是 15
int score = resultProp.stream()
.mapToInt(prop -> optionCount.getOrDefault(prop, 0))
.sum();
if (score > maxScore) {
maxScore = score;
maxScoringResult = scoringResult;
}
}
// 4. 构造返回值,填充答案对象的属性
UserAnswer userAnswer = new UserAnswer();
userAnswer.setAppId(appId);
userAnswer.setAppType(app.getAppType());
userAnswer.setScoringStrategy(app.getScoringStrategy());
userAnswer.setChoices(JSONUtil.toJsonStr(choices));
userAnswer.setResultId(maxScoringResult.getId());
userAnswer.setResultName(maxScoringResult.getResultName());
userAnswer.setResultDesc(maxScoringResult.getResultDesc());
userAnswer.setResultPicture(maxScoringResult.getResultPicture());
return userAnswer;
}
}
得分类评分策略实现类
package com.snowyee.yudada.scoring.impl;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.snowyee.yudada.model.dto.question.QuestionContentDTO;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.Question;
import com.snowyee.yudada.model.entity.ScoringResult;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.model.vo.QuestionVO;
import com.snowyee.yudada.scoring.ScoringStrategy;
import com.snowyee.yudada.scoring.ScoringStrategyConfig;
import com.snowyee.yudada.service.QuestionService;
import com.snowyee.yudada.service.ScoringResultService;
import javax.annotation.Resource;
import java.util.List;
import java.util.Optional;
@ScoringStrategyConfig(appType = 0, scoringStrategy = 0)
public class CustomScoreScoringStrategyImpl implements ScoringStrategy {
@Resource
private QuestionService questionService;
@Resource
private ScoringResultService scoringResultService;
@Override
public UserAnswer doScore(List<String> choices, App app) throws Exception {
// 1. 根据id查询到题目和题目结果信息(按分数降序排序)
Long appId = app.getId();
Question question = questionService.getOne(
Wrappers.lambdaQuery(Question.class)
.eq(Question::getAppId, appId)
);
List<ScoringResult> scoringResultList = scoringResultService.list(
Wrappers.lambdaQuery(ScoringResult.class)
.eq(ScoringResult::getAppId, appId)
.orderByDesc(ScoringResult::getResultScoreRange)
);
// 2. 统计用户的总得分,就是把所有选项的得分累加起来
int totalScore = 0;
QuestionVO questionVO = QuestionVO.objToVo(question);
List<QuestionContentDTO> questionContent = questionVO.getQuestionContent();
for (QuestionContentDTO questionContentDTO : questionContent) {
for (String choice : choices) {
for (QuestionContentDTO.OptionDTO option : questionContentDTO.getOptions()) {
if (option.getResult().equals(choice)) {
Integer scpre = Optional.of(option.getScore()).orElse(0);
totalScore += scpre;
}
}
}
}
// 3. 遍历得分结果,找到第一个用户分数大于得分范围的结果,作为最终结果
ScoringResult maxScoringResult = scoringResultList.get(0);
for (ScoringResult scoringResult : scoringResultList) {
if (totalScore >= scoringResult.getResultScoreRange()) {
maxScoringResult = scoringResult;
break;
}
}
// 4. 构造返回值,填充答案对象的属性
UserAnswer userAnswer = new UserAnswer();
userAnswer.setAppId(appId);
userAnswer.setAppType(app.getAppType());
userAnswer.setScoringStrategy(app.getScoringStrategy());
userAnswer.setChoices(JSONUtil.toJsonStr(choices));
userAnswer.setResultId(maxScoringResult.getId());
userAnswer.setResultName(maxScoringResult.getResultName());
userAnswer.setResultDesc(maxScoringResult.getResultDesc());
userAnswer.setResultPicture(maxScoringResult.getResultPicture());
userAnswer.setResultScore(totalScore);
return userAnswer;
}
}
评分策略配置1(根据app表中的appType应用类型,scoringStrategy得分策略来选择具体的实现类)
直接用swtich方法遍历,不建议使用,因为,策略增加,需要手动添加switch的分类
package com.snowyee.yudada.scoring;
import com.snowyee.yudada.common.ErrorCode;
import com.snowyee.yudada.exception.BusinessException;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.model.enums.AppTypeEnum;
import com.snowyee.yudada.model.enums.ScoringStrategyEnum;
import com.snowyee.yudada.scoring.impl.CustomScoreScoringStrategyImpl;
import com.snowyee.yudada.scoring.impl.CustomTestScoringStrategyImpl;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
@Service
@Deprecated
public class ScoringStrategyContext {
@Resource
private CustomScoreScoringStrategyImpl customScoreScoringStrategy;
@Resource
private CustomTestScoringStrategyImpl customTestScoringStrategy;
/**
* 根据策略类型获取策略对象
*/
public UserAnswer doScore(List<String> choiceList, App app) throws Exception {
AppTypeEnum appTypeEnum = AppTypeEnum.getEnumByValue(app.getAppType());
ScoringStrategyEnum scoringStrategyEnum = ScoringStrategyEnum.getEnumByValue(app.getScoringStrategy());
if (appTypeEnum == null || scoringStrategyEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"应用配置有误,未找到匹配的策略");
}
// 根据不同的应用类型和评分策略,选择对应的策略执行
switch (appTypeEnum) {
case SCORE:
switch (scoringStrategyEnum) {
case CUSTOM:
return customScoreScoringStrategy.doScore(choiceList, app);
case AI:
break;
}
case TEST:
switch (scoringStrategyEnum) {
case CUSTOM:
return customTestScoringStrategy.doScore(choiceList, app);
case AI:
break;
}
break;
}
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"应用配置有误,未找到匹配的策略");
}
}
评分策略配置2(根据app表中的appType应用类型,scoringStrategy得分策略来选择具体的实现类)
使用springboot的注解
注解类ScoringStrategyConfig
package com.snowyee.yudada.scoring;
import org.springframework.stereotype.Component;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Component
public @interface ScoringStrategyConfig {
/**
* 应用类型
* @return
*/
int appType();
/**
* 评分策略
* @return
*/
int scoringStrategy();
}
具体实现方法ScoringStrategyExecutor
package com.snowyee.yudada.scoring;
import com.snowyee.yudada.common.ErrorCode;
import com.snowyee.yudada.exception.BusinessException;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.UserAnswer;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.List;
@Service
public class ScoringStrategyExecutor {
// 策略列表
@Resource
private List<ScoringStrategy> scoringStrategieList;
/**
* 根据策略类型获取策略对象
*/
public UserAnswer doScore(List<String> choiceList, App app) throws Exception {
Integer appType = app.getAppType();
Integer strategy = app.getScoringStrategy();
if (appType == null || strategy == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"应用配置有误,未找到匹配的策略");
}
// 根据注解获取策略
for (ScoringStrategy scoringStrategy : scoringStrategieList) {
if (scoringStrategy.getClass().isAnnotationPresent(ScoringStrategyConfig.class)) {
ScoringStrategyConfig scoringStrategyConfig = scoringStrategy.getClass().getAnnotation(ScoringStrategyConfig.class);
if (scoringStrategyConfig.appType() == appType && scoringStrategyConfig.scoringStrategy() == strategy) {
return scoringStrategy.doScore(choiceList, app);
}
}
}
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"应用配置有误,未找到匹配的策略");
}
}
前端开发
注:我是因为开发前端的经验比较多,这块我比较熟我就没写太详细,如果大家想看详细笔记,可以直接看鱼皮的文字教程
自动生成请求代码
官方文档地址
https://www.npmjs.com/package/@umijs/openapi
1、安装
npm i --save-dev @umijs/openapi
2、在根目录下新建配置openapi.config.ts
const { generateService } = require("@umijs/openapi");
generateService({
requestLibPath: "import request from '@/request'",
schemaPath: "http://localhost:8101/api/v2/api-docs",
serversPath: "./src",
});
全局状态管理(pinia)
官方文档地址
https://pinia.vuejs.org/zh/getting-started.html
1、安装,main.ts
import { createApp } from 'vue'
import { createPinia } from 'pinia'
import App from './App.vue'
const pinia = createPinia()
const app = createApp(App)
app.use(pinia)
app.mount('#app')
2、定义模块,以user模块为例
import { defineStore } from "pinia";
import { ref } from "vue";
import { getLoginUserUsingGet } from "@/api/userController";
export const useLoginUserStore = defineStore("loginUser", () => {
const loginUser = ref<API.LoginUserVO>({
userName: "未登录",
});
async function fetchLoginUser() {
const res = await getLoginUserUsingGet();
if (res.data.code === 0 && res.data.data) {
loginUser.value = res.data.data;
}
}
function setLoginUser(newLoginUser: API.LoginUserVO) {
loginUser.value = newLoginUser;
}
return { loginUser, setLoginUser, fetchLoginUser };
});
4、使用
const loginUserStore = useLoginUserStore();
loginUserStore.fetchLoginUser();
{{loginUserStore.loginUser.userName}}
平台智能化
demo测试接入AI模块
1、先引入maven
<!-- https://open.bigmodel.cn/dev/api#sdk_install -->
<!-- 智谱AISDK调用-->
<dependency>
<groupId>cn.bigmodel.openapi</groupId>
<artifactId>oapi-java-sdk</artifactId>
<version>release-V4-2.0.2</version>
</dependency>
2、配置apikey,写单元测试跑通Demo
package com.snowyee.yudada;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.snowyee.yudada.manager.AiManager;
import com.zhipu.oapi.ClientV4;
import com.zhipu.oapi.Constants;
import com.zhipu.oapi.service.v4.model.ChatCompletionRequest;
import com.zhipu.oapi.service.v4.model.ChatMessage;
import com.zhipu.oapi.service.v4.model.ChatMessageRole;
import com.zhipu.oapi.service.v4.model.ModelApiResponse;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
public class ZHIPUAITest {
@Resource
private ClientV4 clientV4;
@Resource
private AiManager aiManager;
@Test
// 测试直接调用sdk
public void test() {
ClientV4 client = new ClientV4.Builder("你的apikey").build();
List<ChatMessage> messages = new ArrayList<>();
ChatMessage chatMessage = new ChatMessage(ChatMessageRole.USER.value(), "作为一名营销专家,请为智谱开放平台创作一个吸引人的slogan");
messages.add(chatMessage);
// String requestId = String.format(requestIdTemplate, System.currentTimeMillis());
ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder()
.model(Constants.ModelChatGLM4)
.stream(Boolean.FALSE)
.invokeMethod(Constants.invokeMethod)
.messages(messages)
// .requestId(requestId)
.build();
ModelApiResponse invokeModelApiResp = client.invokeModelApi(chatCompletionRequest);
System.out.println("model output:" + invokeModelApiResp.getData().getChoices().get(0));
}
@Test
// 测试在yml配置过apikey的调用
public void test2() {
List<ChatMessage> messages = new ArrayList<>();
ChatMessage chatMessage = new ChatMessage(ChatMessageRole.USER.value(), "作为一名营销专家,请为智谱开放平台创作一个吸引人的slogan");
messages.add(chatMessage);
// String requestId = String.format(requestIdTemplate, System.currentTimeMillis());
ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder()
.model(Constants.ModelChatGLM4)
.stream(Boolean.FALSE)
.invokeMethod(Constants.invokeMethod)
.messages(messages)
// .requestId(requestId)
.build();
ModelApiResponse invokeModelApiResp = clientV4.invokeModelApi(chatCompletionRequest);
System.out.println("model output:" + invokeModelApiResp.getData().getChoices().get(0));
}
@Test
// 测试封装好的调用好不好使
public void test3() {
String output = aiManager.doSyncStableRequest("问你是谁,你要回答我是程序媛雪儿", "你是谁啊?");
System.out.println("model output:" + output);
}
}
一个比较坑的点,如果debug报错,可以打开如下配置
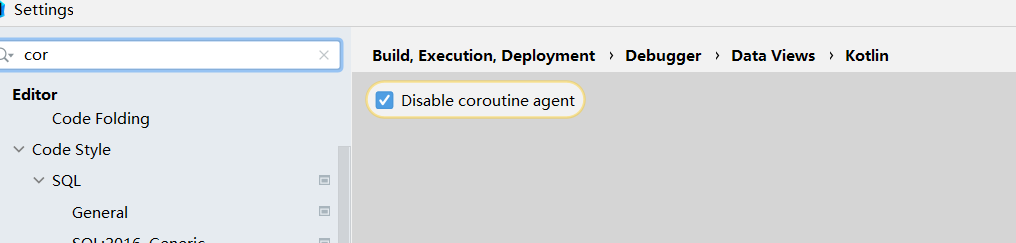
封装AI模块
1、在application.yml中配置
# 智谱ai配置
ai:
apiKey: xxx
2、定义配置类
package com.snowyee.yudada.config;
import com.zhipu.oapi.ClientV4;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties(prefix = "ai")
@Data
public class AiConfig {
/**
* ai key,需要从智谱ai平台获取
*/
private String apiKey;
@Bean
public ClientV4 getClientV4() {
return new ClientV4.Builder(apiKey).build();
}
}
3、封装请求,使得请求简化
package com.snowyee.yudada.manager;
import com.snowyee.yudada.common.ErrorCode;
import com.snowyee.yudada.exception.BusinessException;
import com.zhipu.oapi.ClientV4;
import com.zhipu.oapi.Constants;
import com.zhipu.oapi.service.v4.model.*;
import io.reactivex.Flowable;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
@Component
public class AiManager {
@Resource
private ClientV4 clientV4;
// 稳定的随机数
private static final float STABLE_TEMPERATURE = 0.05f;
// 不稳定的随机数
private static final float UNSTABLE_TEMPERATURE = 0.99f;
/**
* 通用同步请求(不稳定版)
* @param systemMessage
* @param userMessage
* @return
*/
public String doSyncUnstableRequest(String systemMessage, String userMessage){
return doSyncRequest(systemMessage, userMessage, UNSTABLE_TEMPERATURE);
}
/**
* 通用同步请求(稳定版)
* @param systemMessage
* @param userMessage
* @return
*/
public String doSyncStableRequest(String systemMessage, String userMessage){
return doSyncRequest(systemMessage, userMessage, STABLE_TEMPERATURE);
}
/**
* 通用同步请求
* @param systemMessage
* @param userMessage
* @param temperature
* @return
*/
public String doSyncRequest(String systemMessage, String userMessage,Float temperature){
return doRequest(systemMessage, userMessage, Boolean.FALSE, temperature);
}
/**
* 通用请求(简化消息传递)
* @param systemMessage
* @param userMessage
* @param stream
* @param temperature
* @return
*/
public String doRequest(String systemMessage, String userMessage,Boolean stream,Float temperature){
List<ChatMessage> chatMessageList = new ArrayList<>();
ChatMessage systemChatMessage = new ChatMessage(ChatMessageRole.SYSTEM.value(), systemMessage);
chatMessageList.add(systemChatMessage);
ChatMessage userChatMessage = new ChatMessage(ChatMessageRole.USER.value(), userMessage);
chatMessageList.add(userChatMessage);
return doRequest(chatMessageList,stream,temperature);
}
/**
* 通用方法调用接口
* @param messages
* @param stream
* @param temperature
* @return
*/
public String doRequest(List<ChatMessage> messages,Boolean stream,Float temperature){
ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder()
.model(Constants.ModelChatGLM4)
.stream(stream)
.temperature(temperature)
.invokeMethod(Constants.invokeMethod)
.messages(messages)
.build();
try {
ModelApiResponse invokeModelApiResp = clientV4.invokeModelApi(chatCompletionRequest);
return invokeModelApiResp.getData().getChoices().get(0).toString();
}catch (Exception e){
e.printStackTrace();
throw new BusinessException(ErrorCode.SYSTEM_ERROR,e.getMessage());
}
}
/**
* 通用方法流式调用接口
* @param messages
* @param temperature
* @return
*/
public Flowable<ModelData> doStreamRequest(List<ChatMessage> messages, Float temperature){
ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder()
.model(Constants.ModelChatGLM4)
.stream(Boolean.TRUE)
.temperature(temperature)
.invokeMethod(Constants.invokeMethod)
.messages(messages)
.build();
try {
ModelApiResponse invokeModelApiResp = clientV4.invokeModelApi(chatCompletionRequest);
// 返回的数据是流式的
return invokeModelApiResp.getFlowable();
}catch (Exception e){
e.printStackTrace();
throw new BusinessException(ErrorCode.SYSTEM_ERROR,e.getMessage());
}
}
/**
* 通用流式请求(简化消息传递)
* @param systemMessage
* @param userMessage
* @param temperature
* @return
*/
public Flowable<ModelData> doStreamRequest(String systemMessage, String userMessage, Float temperature){
List<ChatMessage> chatMessageList = new ArrayList<>();
ChatMessage systemChatMessage = new ChatMessage(ChatMessageRole.SYSTEM.value(), systemMessage);
chatMessageList.add(systemChatMessage);
ChatMessage userChatMessage = new ChatMessage(ChatMessageRole.USER.value(), userMessage);
chatMessageList.add(userChatMessage);
return doStreamRequest(chatMessageList,temperature);
}
}
AI生成题目
需求分析
手动一个一个添加标题和选项比较麻烦,我们可以使用AI,根据已经填写的应用信息,自动生成题目,然后再由人工编辑确认,提高创建题目的效率。
prompt设计
系统prompt
你是一位严谨的出题专家,我会给你如下信息:
```
应用名称,
【【【应用描述】】】,
应用类别,
要生成的题目数,
每个题目的选项数
```
请你根据上述信息,按照以下步骤来出题:
1. 要求:题目和选项尽可能地短,题目不要包含序号,每题的选项数以我提供的为主,题目不能重复
2. 严格按照下面的 json 格式输出题目和选项
```
[{"options":[{"value":"选项内容","key":"A","result":"E","score":1},{"value":"","key":"B","result":"N","score":1}],"title":"题目标题"}]
```
title 是题目,options 是选项,每个选项的 key 按照英文字母序(比如 A、B、C、D)以此类推,value 是选项内容, 如果是测评类应用,result是某个测评结果选项,score为0,如果得分类应用,result为空,score是指定的分数上限
3. 检查题目是否包含序号,若包含序号则去除序号
4. 返回的题目列表格式必须为 JSON 数组
用户prompt
MBTI 性格测试,
【【【测试你的性格,问题是提供给个体回答的,不是让用户理解MBTI是什么,而是直接测试一个人的性格】】】,
测评类,
10,
2
prompt编写技巧
1、定义系统prompt
2、给大模型一个角色,比如,你是一位严谨的出题专家
3、使用分隔符表示不同的输入部分
4、少样本学习
5、指定输出长度
6、将复杂任务分解为简单的子任务(告诉大模型每步要做什么)
7、指定固定的输出格式
8、通过按顺序输入参数来节约空间
9、对于描述这种多行的内容,可以用特殊字符括起来,防止用户输入过多干扰生成结果,【【【】】】像这样子括起来
代码开发
1、AI生成题目请求类
package com.snowyee.yudada.model.dto.question;
import lombok.Data;
import java.io.Serializable;
/**
* AI 生成题目请求
*/
@Data
public class AiGenerateQuestionRequest implements Serializable {
/**
* 应用id
*/
private Long appId;
/**
* 题目数量
*/
int questionNumber = 5;
/**
* 题目选项数量
*/
int optionNumber = 2;
}
2、定义系统prompt,拼接用户prompt
// region AI生成题目功能
private static final String GENERATE_QUESTION_SYSTEM_MESSAGE = "你是一位严谨的出题专家,我会给你如下信息:\n" +
"```\n" +
"应用名称,\n" +
"【【【应用描述】】】,\n" +
"应用类别,\n" +
"要生成的题目数,\n" +
"每个题目的选项数\n" +
"```\n" +
"\n" +
"请你根据上述信息,按照以下步骤来出题:\n" +
"1. 要求:题目和选项尽可能地短,题目不要包含序号,每题的选项数以我提供的为主,题目不能重复\n" +
"2. 严格按照下面的 json 格式输出题目和选项\n" +
"```\n" +
"[{\"options\":[{\"value\":\"选项内容\",\"key\":\"A\",\"result\":\"E\",\"score\":1},{\"value\":\"\",\"key\":\"B\",\"result\":\"N\",\"score\":1}],\"title\":\"题目标题\"}]\n" +
"```\n" +
"title 是题目,options 是选项,每个选项的 key 按照英文字母序(比如 A、B、C、D)以此类推,value 是选项内容, 如果是测评类应用,result是某个测评结果选项,score为0,如果得分类应用,result为空,score是指定的分数上限\n" +
"3. 检查题目是否包含序号,若包含序号则去除序号\n" +
"4. 返回的题目列表格式必须为 JSON 数组";
/**
* 生成题目的用户消息
* MBTI 性格测试,
* 【【【快来测测你的 MBTI 性格】】】,
* 测评类,
* 10,
* 3
* 生成示例
*
* @param app
* @param questionNumber
* @param optionNumber
* @return
*/
private String getGenerateQuestionUserMessage(App app, int questionNumber, int optionNumber) {
StringBuilder userMessage = new StringBuilder();
userMessage.append(app.getAppName()).append("\n");
userMessage.append(app.getAppDesc()).append("\n");
userMessage.append(AppTypeEnum.getEnumByValue(app.getAppType()).getText() + "类").append("\n");
userMessage.append(questionNumber).append("\n");
userMessage.append(optionNumber);
return userMessage.toString();
}
3、在controller中写AI生成的接口
// 生成AI题目
@PostMapping("/ai_generate")
public BaseResponse<List<QuestionContentDTO>> aiGenerateQuestion(
@RequestBody AiGenerateQuestionRequest aiGenerateQuestionRequest
){
ThrowUtils.throwIf(aiGenerateQuestionRequest == null, ErrorCode.PARAMS_ERROR);
// 获取参数
Long appId = aiGenerateQuestionRequest.getAppId();
int questionNumber = aiGenerateQuestionRequest.getQuestionNumber();
int optionNumber = aiGenerateQuestionRequest.getOptionNumber();
// 获取应用信息
App app = appService.getById(appId);
ThrowUtils.throwIf(app == null, ErrorCode.NOT_FOUND_ERROR);
// 封装prompt
String userMessage = getGenerateQuestionUserMessage(app, questionNumber, optionNumber);
// AI生成题目
String result = aiManager.doSyncRequest(GENERATE_QUESTION_SYSTEM_MESSAGE, userMessage,null);
// 解析返回的题目
int start = result.indexOf("[");
int end = result.lastIndexOf("]");
String json = result.substring(start, end + 1);
List<QuestionContentDTO> questionContentDTOList = JSONUtil.toList(json, QuestionContentDTO.class);
return ResultUtils.success(questionContentDTOList);
}
// endregion
AI智能评分
需求分析
原本需要应用创建者自己创建评分结果,并且给题目选项设置得分和对应的属性,比较麻烦,如果使用AI,AI可以根据应用信息、题目和用户的答案进行评分,直接返回评分结果,比较适用测评类的评分结果。
prompt设计
1、输入参数
{
"appName": "MBTI 性格测试",
"appDesc": "测试你的 MBTI 性格",
"question": [
{
"title":"你喜欢和人交流",
"answer": "喜欢"
}
]
}
2、返回结果
{
"resultName":"INTJ",
"resultDesc": "INTJ被称为'策略家'或'建筑师',是一个高度独立和具有战略思考能力的性格类型"
}
系统prompt
你是一位严谨的判题专家,我会给你如下信息:
```
应用名称,
【【【应用描述】】】,
题目和用户回答的列表:格式为 [{"title": "题目","answer": "用户回答"}]
```
请你根据上述信息,按照以下步骤来对用户进行评价:
1.要求:需要给出一个明确的评价结果,包括评价名称(尽量简短)和评价描述(尽量详细,大于 200 字)
2.严格按照下面的 json 格式输出评价名称和评价描述
```
{"resultName": "评价名称,评价名称必须是MBTI16种人格中的一种", "resultDesc":"评价描述"}
```
3.返回格式必须为 JSON 对象
用户prompt
MBTI 性格测试,
【【【快来测测你的 MBTI 性格】】】,
[{"title":"你通常更喜欢","answer": "独自工作"}, {"title": "当安排活动时","answer": "更愿意随机应变"}]
代码开发
在后端开发的时候,我们不是实现了自动匹配评分策略选择评分方案嘛,这个时候直接写一个AiTestScoringStrategyImpl实现类就好了
1、题目答案封装类
package com.snowyee.yudada.model.dto.question;
import lombok.Data;
/**
* 题目答题封装类(用于AI评分)
*/
@Data
public class QuestionAnswerDTO {
/**
* 题目
*/
private String title;
/**
* 用户答案
*/
private String userAnswer;
}
2、AiTestScoringStrategyImpl实现类
package com.snowyee.yudada.scoring.impl;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.snowyee.yudada.manager.AiManager;
import com.snowyee.yudada.model.dto.question.QuestionAnswerDTO;
import com.snowyee.yudada.model.dto.question.QuestionContentDTO;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.Question;
import com.snowyee.yudada.model.entity.ScoringResult;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.model.vo.QuestionVO;
import com.snowyee.yudada.scoring.ScoringStrategy;
import com.snowyee.yudada.scoring.ScoringStrategyConfig;
import com.snowyee.yudada.service.QuestionService;
import com.snowyee.yudada.service.ScoringResultService;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* AI 测评类应用评分策略
*/
@ScoringStrategyConfig(appType = 1, scoringStrategy = 1)
public class AiTestScoringStrategyImpl implements ScoringStrategy {
@Resource
private QuestionService questionService;
@Resource
private AiManager aiManager;
/**
* 评分系统prompt
*/
private static final String AI_TEST_SCORING_SYSTEM_MESSAGE = "你是一位严谨的判题专家,我会给你如下信息:\n" +
"```\n" +
"应用名称,\n" +
"【【【应用描述】】】,\n" +
"题目和用户回答的列表:格式为 [{\"title\": \"题目\",\"answer\": \"用户回答\"}]\n" +
"```\n" +
"\n" +
"请你根据上述信息,按照以下步骤来对用户进行评价:\n" +
"1.要求:需要给出一个明确的评价结果,包括评价名称(尽量简短)和评价描述(尽量详细,大于 200 字)\n" +
"2.严格按照下面的 json 格式输出评价名称和评价描述\n" +
"```\n" +
"{\"resultName\": \"评价名称,评价名称必须是MBTI16种人格中的一种\", \"resultDesc\":\"评价描述\"}\n" +
"```\n" +
"3.返回格式必须为 JSON 对象";
@Override
public UserAnswer doScore(List<String> choices, App app) throws Exception {
// 1. 根据id查询到题目和题目结果信息
Long appId = app.getId();
Question question = questionService.getOne(
Wrappers.lambdaQuery(Question.class)
.eq(Question::getAppId, appId)
);
QuestionVO questionVO = QuestionVO.objToVo(question);
List<QuestionContentDTO> questionContent = questionVO.getQuestionContent();
// 2. 调用AI获取结果
// 封装 userMessage的prompt
String userMessage = getAiTestScoringUserMessage(app, questionContent, choices);
// AI 生成答案
String result = aiManager.doSyncStableRequest(AI_TEST_SCORING_SYSTEM_MESSAGE, userMessage);
// 截取需要的JSON信息
int start = result.indexOf("{");
int end = result.lastIndexOf("}");
String resultJson = result.substring(start, end + 1);
// 4. 构造返回值,填充答案对象的属性
UserAnswer userAnswer = JSONUtil.toBean(resultJson, UserAnswer.class);
userAnswer.setAppId(appId);
userAnswer.setAppType(app.getAppType());
userAnswer.setScoringStrategy(app.getScoringStrategy());
userAnswer.setChoices(JSONUtil.toJsonStr(choices));
return userAnswer;
}
/**
* 评分用户prompt
*/
private String getAiTestScoringUserMessage(App app ,List<QuestionContentDTO> questionContentDTOList,List<String> choices){
StringBuilder userMessage = new StringBuilder();
userMessage.append(app.getAppName()).append("\n");
userMessage.append(app.getAppDesc()).append("\n");
List<QuestionAnswerDTO> questionAnswerDTOList = new ArrayList<>();
for(int i = 0 ; i < questionContentDTOList.size(); i++){
QuestionAnswerDTO questionAnswerDTO = new QuestionAnswerDTO();
questionAnswerDTO.setTitle(questionContentDTOList.get(i).getTitle());
// 我感觉这块有点不对劲,choices.get(i)是【A,B,A,A】这种,不带文字的,而我们喂给AI的prompt应该是
/**
* MBTI 性格测试,
* 【【【快来测测你的 MBTI 性格】】】,
* [{"title":"你通常更喜欢","answer": "独自工作"}, {"title": "当安排活动时","answer": "更愿意随机应变"}]
* 这样的格式,应该处理成文字才对
*/
questionAnswerDTO.setUserAnswer(choices.get(i));
questionAnswerDTOList.add(questionAnswerDTO);
}
userMessage.append(JSONUtil.toJsonStr(questionAnswerDTOList));
return userMessage.toString();
}
}
Spring AI
这是一个简化AI应用程序开发的工具库
官方文档地址:https://docs.spring.io/spring-ai/reference/
Spring AI是基于jdk17构建的,简单说,Spring AI整合了多个大模型,可以让调用多个大模型的方式统一,感觉调用方式上并没有变的更简单
操作步骤
1、引入依赖
<dependency>
<groupId>io.springboot.ai</groupId>
<artifactId>spring-ai-zhipu-ai-spring-boot-starter</artifactId>
<version>1.0.3</version>
</dependency>
2、配置文件
spring:
ai:
zhipuai:
api-key: xxxx
chat:
enabled: true
options:
model: glm-4
3、使用大模型
@Resource
private ZhipuAiChatClient chatClient;
//简单调用
chatClient.call("给我讲一个笑话");
//也可以配置一些参数
ChatResponse response = chatClient.call(
new Prompt(
"帮我随机生成五个名字",
ZhipuAiChatOptions.builder()
.withModel("glm-4")
.withTemperature(0.8)
.build()
));
性能优化
RxJava响应式编程
需求背景:之前AI生成相关的功能是等所有内容全部生成后,再返回给前端,前端用户等待的时间太长了,那么能不能生成一道题就给前端展示一道题呢?
大致思路:开启智谱AI流式调用方式,智谱AI实时生成数据,后端实时接收数据,等到一个完整的题目出现,后端把整个题目json实时传给前端,前端实时的展现
什么是响应式编程?
响应式编程是一种编程范式,它专注于异步数据流和变化传播。
数据流:数据以流的形式存在。数据流可以被过滤、观测、或者跟另一条河流合并成一个新的流。
用户输入、网络请求、文件读取都可以是数据流,可以很轻松地对流进行处理
异步处理:操作不会阻塞线程,而是通过回调在某个时间点处理结果。这提高了应用的响应性和性能。
变化传播:当数据源发生变化的时候,响应式编程模型会自动把变化的数据传给订阅者
常用响应式框架(RxJava)
RxJava是一个基于事件驱动的、利用可观测序列来实现异步编程的类库
1、事件驱动
事件可以是任何事情。比如用户的点击操作、网络请求的结果、文件的读写等
2、可观测序列
可观测序列指一系列按照时间序列发出的数据项,可以被观察处理
RxJava的核心知识点
观察者模式
RxJava是基于观察者模式实现的。
观察者:观测数据流 observer
被观察者:实时传输数据流 observable和flowable
observable适合处理相对较小的、可控的、不会产生大量数据的场景,不具备背压能力
flowable具备背压能力。也就是说,如果生产数据过快,超过了大多数数据消费者速度,flowable提供了多种背压策略来处理这种情况,保证大量数据仍然能稳定
建立订阅关系 被观察者.subscribe(观察者)
demo演示
1、引入依赖
因为智谱AI默认引入了2.x版本的RxJava,我们的项目中可以并不引入依赖
2、编写单元测试
package com.snowyee.yudada;
import io.reactivex.Flowable;
import io.reactivex.schedulers.Schedulers;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.concurrent.TimeUnit;
@SpringBootTest
public class RxJavaTest {
/**
* 测试RxJava流式调用
*/
@Test
public void test() throws InterruptedException {
// 发布者创建数据流
Flowable<Long> flowable = Flowable.interval(1, TimeUnit.SECONDS)
.map(i -> i + 1)
.subscribeOn(Schedulers.io());// 指定subscribe()所在的线程
// 订阅 Flowable,并打印出每个接收到的数字
flowable
// 指定观察者的线程
.observeOn(Schedulers.io())
// 每接收一个字符就会调用一次这个函数
.doOnNext(item -> System.out.println(item.toString()))
// 观察者完成订阅
.subscribe();
// 主线程睡眠,以便观察到结果
Thread.sleep(10000L);
}
}
AI生成题目优化
需求分析
如果用户想要生成的题目过多,生成题目的时间超过了前端设置的60s,那就会显示请求超时,而且界面上没有响应,用户体验不佳
需要流式化改造AI生成的题目接口,一道题一道题实时的把题目返回给前端
前后端实时通讯方案
几种主流的实现方案:
1、轮询
前端隔一段时间向后端调用一次接口,比如200ms一次,后端处理一些结果就累加放置到缓存中
2、SSE(后端主动推送给前端)
前端发请求并和后端建立连接,后端实时推动数据给前端
SSE的重要特点
- 单向通信:SSE只支持服务器向客户端的单向通信
- 文本格式:SSE使用纯文本格式传输数据,HTTP响应的text/event-stream
- 保持连接:SSE会保持一个持久的HTTP连接,实现服务器向客户端推送数据
- 自动重连:如果连接中断,浏览器会尝试自动重连
应用场景
- AI对话
- 实时更新:股票价格、体育比赛比分、新闻更新
- 日志监控
- 通知系统
3、WebSocket
全双工协议,前端能实时推送数据给后端,后端也可以实时推送数据给前端
实现我们的需求,选用的技术是SSE。
因为主动轮询是一种伪实时,如果3s一次请求,后端0.1s返回数据,那么就存在2.9s的延时
而webscket是二进制协议,实现起来更复杂
我们的需求是服务器给客户端实时推送一道一道的题目,SSE比较合适。
后端代码
// region
// 生成AI题目流式生成
@GetMapping("/ai_generate/sse")
public SseEmitter aiGenerateQuestionSSE(AiGenerateQuestionRequest aiGenerateQuestionRequest){
ThrowUtils.throwIf(aiGenerateQuestionRequest == null, ErrorCode.PARAMS_ERROR);
// 获取参数
Long appId = aiGenerateQuestionRequest.getAppId();
int questionNumber = aiGenerateQuestionRequest.getQuestionNumber();
int optionNumber = aiGenerateQuestionRequest.getOptionNumber();
// 获取应用信息
App app = appService.getById(appId);
ThrowUtils.throwIf(app == null, ErrorCode.NOT_FOUND_ERROR);
// 封装prompt
String userMessage = getGenerateQuestionUserMessage(app, questionNumber, optionNumber);
// 建立SSE连接对象,0表示永不超时
SseEmitter sseEmitter = new SseEmitter(0L);
// AI生成,SSE流式返回
Flowable<ModelData> modelDataFlowable = aiManager.doStreamRequest(GENERATE_QUESTION_SYSTEM_MESSAGE, userMessage, null);
// 左括号计数器,除了默认之外,当回归为0时,表示左括号 = 右括号,可以截取
AtomicInteger counter = new AtomicInteger(0);
// 拼接完整的题目
StringBuilder stringBuilder = new StringBuilder();
// 截取一道一道的题目进行返回
modelDataFlowable
// 指定观察者的线程池
.observeOn(Schedulers.io())
// 先获取数据
.map(modelData -> modelData.getChoices().get(0).getDelta().getContent())
// 先处理数据把没用的空格都去掉
.map(message -> message.replaceAll("\\s",""))
.filter(StrUtil::isNotBlank)
.flatMap(message ->{
List<Character> characterList = new ArrayList<>();
for (char c : message.toCharArray()) {
characterList.add(c);
}
return Flowable.fromIterable(characterList);
})
// 左右括号{}抵消 就返回数据
.doOnNext(c -> {
// 如果是{ , 计数器+1
if (c == '{') {
counter.addAndGet(1);
}
if(counter.get() > 0) {
stringBuilder.append(c);
}
if (c == '}') {
counter.addAndGet(-1);
if (counter.get() == 0) {
// 拼接题目,并通过SSE返回给前端
sseEmitter.send(JSONUtil.toJsonStr(stringBuilder.toString()));
// 重置,准备下一道题
stringBuilder.setLength(0);
}
}
})
.doOnError((e) -> log.error("AI生成题目异常", e))
.doOnComplete(()->{
sseEmitter.complete();
})
.subscribe();
return sseEmitter;
}
// endregion
前端开发
/**
* 提交流式生成题目,一个一个的生成题目
*/
const handleSSESubmit = async () => {
if (!props.appId) {
return;
}
realtimesubmitting.value = true;
// 创建SSE请求
const eventSource = new EventSource(
// 手动填写完整的后端地址
"http://localhost:8101/api/question/ai_generate/sse?"+`appId=${props.appId}&optionNumber=${form.optionNumber}&questionNumber=${form.questionNumber}`
);
let first = true;
// 接收消息
eventSource.onmessage = function(event) {
console.log(event.data);
if(first){
props.onSSEStart?.(event);
handleCancel();
first = !first;
}
props.onSSESuccess?.(JSON.parse(event.data));
};
// 报错或连接关闭时触发
eventSource.onerror = function(event) {
// 关闭SSE连接
if(event.eventPhase === EventSource.CLOSED){
console.log('关闭连接');
eventSource.close();
props.onSSEClose?.(event);
}
};
// 连接打开时触发
eventSource.onopen = function(event) {
console.log('连接成功');
props.onSSEStart?.(event);
handleCancel();
};
};
AI评分优化
需求分析
1、理论上讲,用户对同一应用的题目做出相同的选择,得到的解答应该是一样的,不应该每次都询问AI,同时每次都调用AI作为评分结果,响应时间也过长,效率不高
2、如果攻击者越过前端页面,直接访问接口,在短时间访问AI生成结果的接口,可能会导致我们的系统一直调用AI大模型,造成计费不说,很有可能被大模型方被认为是攻击者,直接把我们账号禁了。
方案设计
基本思路:对同一账户用于应用下的评分答案做缓存,在短时间内再次答题,我们可以根据缓存直接给答案
1、使用什么缓存呢?
咱们的项目不考虑分布式扩容,不要求持久化,所以我们的方案是caffeine本地缓存
缓存设计
缓存key,我们可以将应用id和用户答案列表作为key,但因为答案列表过长,我们可以用哈希算法(md5)来压缩key
缓存value,AI的回答结果
缓存过期时间,设置为1天
2、大量请求访问AI生成结果接口造成的缓存击穿怎么解决?
加锁,使用redission便捷实现分布式锁
后端代码
1、导包
<!-- 分布式锁-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.21.0</version>
</dependency>
<!-- 缓存-->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
2、具体代码
在pom文件中补充redis配置,在main入口中把exclude redis去掉
Reddsion配置类
package com.snowyee.yudada.config;
import lombok.Data;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties(prefix = "spring.redis")
@Data
public class RedissonConfig {
private String host;
private Integer port;
private Integer database;
private String password;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://" + host + ":" + port)
.setDatabase(database)
.setPassword(password);
return Redisson.create(config);
}
}
AI答题策略实现类
package com.snowyee.yudada.scoring.impl;
import cn.hutool.core.util.StrUtil;
import cn.hutool.crypto.digest.DigestUtil;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.snowyee.yudada.manager.AiManager;
import com.snowyee.yudada.model.dto.question.QuestionAnswerDTO;
import com.snowyee.yudada.model.dto.question.QuestionContentDTO;
import com.snowyee.yudada.model.entity.App;
import com.snowyee.yudada.model.entity.Question;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.model.vo.QuestionVO;
import com.snowyee.yudada.scoring.ScoringStrategy;
import com.snowyee.yudada.scoring.ScoringStrategyConfig;
import com.snowyee.yudada.service.QuestionService;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* AI 测评类应用评分策略
*/
@ScoringStrategyConfig(appType = 1, scoringStrategy = 1)
public class AiTestScoringStrategyImpl implements ScoringStrategy {
@Resource
private QuestionService questionService;
@Resource
private AiManager aiManager;
@Resource
private RedissonClient redissonClient;
// 分布式锁的key
private static final String AI_ANSWER_LOCK = "AI_ANSWER_LOCK";
/**
* 本地缓存
*/
private final Cache<String, String> answerCacheMap =
Caffeine.newBuilder().initialCapacity(1024)
.expireAfterAccess(5L, TimeUnit.MINUTES)
.build();
/**
* 构建缓存key
*/
private String buildCacheKey(Long appId, String choices) {
return DigestUtil.md5Hex(appId +":"+ choices);
}
/**
* 评分系统prompt
*/
private static final String AI_TEST_SCORING_SYSTEM_MESSAGE = "你是一位严谨的判题专家,我会给你如下信息:\n" +
"```\n" +
"应用名称,\n" +
"【【【应用描述】】】,\n" +
"题目和用户回答的列表:格式为 [{\"title\": \"题目\",\"answer\": \"用户回答\"}]\n" +
"```\n" +
"\n" +
"请你根据上述信息,按照以下步骤来对用户进行评价:\n" +
"1.要求:需要给出一个明确的评价结果,包括评价名称(尽量简短)和评价描述(尽量详细,大于 200 字)\n" +
"2.严格按照下面的 json 格式输出评价名称和评价描述\n" +
"```\n" +
"{\"resultName\": \"评价名称,评价名称必须是MBTI16种人格中的一种\", \"resultDesc\":\"评价描述\"}\n" +
"```\n" +
"3.返回格式必须为 JSON 对象";
@Override
public UserAnswer doScore(List<String> choices, App app) throws Exception {
// 1. 根据id查询到题目和题目结果信息
Long appId = app.getId();
// 缓存appid+choices+answerJson, 用md5加密后缓存
String jsonChoices = JSONUtil.toJsonStr(choices);
String cacheKey = buildCacheKey(appId, jsonChoices);
/**
* getIfPresent(cacheKey): 这是一个方法,用于从缓存中获取与 cacheKey 相关联的值。如果缓存中存在该键的值,则返回该值;如果不存在,则返回 null。
*/
String answerJson = answerCacheMap.getIfPresent(cacheKey);
// 如果有缓存,直接返回
if (StrUtil.isNotBlank(answerJson)) {
// 构造返回值,填充答案对象的属性
UserAnswer userAnswer = JSONUtil.toBean(answerJson, UserAnswer.class);
userAnswer.setAppId(appId);
userAnswer.setAppType(app.getAppType());
userAnswer.setScoringStrategy(app.getScoringStrategy());
userAnswer.setChoices(jsonChoices);
return userAnswer;
}
// 定义锁
RLock lock = redissonClient.getLock(AI_ANSWER_LOCK + cacheKey);
try{
// 竞争锁
/**
* time(第一个参数,3):表示在尝试获取锁时的初始等待时间。这里设置为 3。
* time(第二个参数,15):表示在尝试获取锁时的最大等待时间。这里设置为 15。
* unit(第三个参数,TimeUnit.SECONDS):表示时间单位,这里使用的是秒 (SECONDS)。
*
* 初始等待时间 是线程第一次尝试获取锁时的等待时间,可以用来减少无效的等待。
* 最大等待时间 是线程总共尝试获取锁的最大时间,防止线程无限等待锁的情况。
*
* 我做这块的时候,有个问题,设置这3s有什么意义,直接等15s不行吗,为什么要等3s获取不到,再继续等?
*
* 原因:
* 避免长时间阻塞:在某些情况下,线程可能会在尝试获取锁时遇到短暂的阻塞。通过设置一个较短的初始等待时间,线程可以先尝试获取锁。如果在短时间内成功获取锁,那么它就不必一直等待。这样可以减少无效等待,提高系统响应速度。
*
* 适应性重试:初始等待时间为线程提供了一个快速重试的机会。如果锁在短时间内可用,线程可以立即继续执行,而不必等待整个最大等待时间。这样可以提高锁获取的成功率,特别是在锁的持有时间较短的情况下。
*
*/
boolean res = lock.tryLock(3, 15, TimeUnit.SECONDS);
// 获取不到锁,直接返回
if (!res){
return null;
}
Question question = questionService.getOne(
Wrappers.lambdaQuery(Question.class)
.eq(Question::getAppId, appId)
);
QuestionVO questionVO = QuestionVO.objToVo(question);
List<QuestionContentDTO> questionContent = questionVO.getQuestionContent();
// 2. 调用AI获取结果
// 封装 userMessage的prompt
String userMessage = getAiTestScoringUserMessage(app, questionContent, choices);
// AI 生成答案
String result = aiManager.doSyncStableRequest(AI_TEST_SCORING_SYSTEM_MESSAGE, userMessage);
// 截取需要的JSON信息
int start = result.indexOf("{");
int end = result.lastIndexOf("}");
String resultJson = result.substring(start, end + 1);
// 缓存结果
answerCacheMap.put(cacheKey, resultJson);
// 4. 构造返回值,填充答案对象的属性
UserAnswer userAnswer = JSONUtil.toBean(resultJson, UserAnswer.class);
userAnswer.setAppId(appId);
userAnswer.setAppType(app.getAppType());
userAnswer.setScoringStrategy(app.getScoringStrategy());
userAnswer.setChoices(jsonChoices);
return userAnswer;
}finally {
if (lock != null && lock.isLocked()){
// 为了确保只有持有锁的线程才能释放锁,如果一个线程试图释放它没有持有的锁,可能引发死锁。
if (lock.isHeldByCurrentThread()){
lock.unlock();
}
}
}
}
/**
* 评分用户prompt
*/
private String getAiTestScoringUserMessage(App app, List<QuestionContentDTO> questionContentDTOList, List<String> choices) {
StringBuilder userMessage = new StringBuilder();
userMessage.append(app.getAppName()).append("\n");
userMessage.append(app.getAppDesc()).append("\n");
List<QuestionAnswerDTO> questionAnswerDTOList = new ArrayList<>();
for (int i = 0; i < questionContentDTOList.size(); i++) {
QuestionAnswerDTO questionAnswerDTO = new QuestionAnswerDTO();
questionAnswerDTO.setTitle(questionContentDTOList.get(i).getTitle());
// 我感觉这块有点不对劲,choices.get(i)是【A,B,A,A】这种,不带文字的,而我们喂给AI的prompt应该是
/**
* MBTI 性格测试,
* 【【【快来测测你的 MBTI 性格】】】,
* [{"title":"你通常更喜欢","answer": "独自工作"}, {"title": "当安排活动时","answer": "更愿意随机应变"}]
* 这样的格式,应该处理成文字才对
*/
questionAnswerDTO.setUserAnswer(choices.get(i));
questionAnswerDTOList.add(questionAnswerDTO);
}
userMessage.append(JSONUtil.toJsonStr(questionAnswerDTOList));
return userMessage.toString();
}
}
分库分表
需求分析
一般这个技术用不到,但是如果我们的平台发展迅猛,用户量激增,哪个表数据会最大呢?
因为一个用户可能会对同一个应用多次答题,也可以对多个应用答题,所以,理论上用户量足够大,最先遇到瓶颈的是user_answer用户答题记录表
解决方案
把user_answer分成多个表,比如user_answer0/user_answer1
其实像比较火爆的电商网站的订单表,如果赶上促销活动,这个表必然激增,也可以用相同的方法,按照时间的维度分表,如order_202401,order_202402这样子拆
技术选型
去github上查,可以根据star数来选,开源组件有ShardingSphere、MyCat、Cobar等
基本上选最活跃的,项目迭代比较快,使用次数比较多的就可以
本次选用Sharding-JDBC
Sharding-JDBC原理
改写sql,比如在我们的项目中,如果我们的设计是appId%2==0的答题记录放到user_answer_0,appId%2==1的答题记录放到user_answer_1,Sharding-JDBC就会根据你设定的规则改写sql,在执行save的时候,表名会动态变化。
后端代码
1、新建user_answer_0,user_answer_1表
2、导包
<!-- 实现分库分表-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.0</version>
</dependency>
3、在application.yml中配置
# 分库分表配置
shardingsphere:
# 数据源配置
datasource:
# 多数据源以逗号隔开即可
names: yudada
yudada:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xx.xx.xx.xx:xx/xx
username: root
password: xxxx
# 规则配置
rules:
sharding:
# 分片算法配置
sharding-algorithms:
# 自定义分片规则名
answer-table-inline:
type: INLINE
props:
algorithm-expression: user_answer_$->{appId % 2}
tables:
user_answer:
actual-data-nodes: yudada.user_answer_$->{0..1}
# 分表策略
table-strategy:
standard:
sharding-column: appId
sharding-algorithm-name: answer-table-inline
4、上面完成就可以正常使用了,可以写测试类测试
package com.snowyee.yudada;
import cn.hutool.json.JSONUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.snowyee.yudada.model.entity.UserAnswer;
import com.snowyee.yudada.service.UserAnswerService;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
public class UserAnswerShardingTest {
@Resource
private UserAnswerService userAnswerService;
@Test
public void test(){
UserAnswer userAnswer1 = new UserAnswer();
// 我们设置的是根据AppId分表的
userAnswer1.setAppId(1L);
userAnswer1.setUserId(1809119229891362817L);
userAnswer1.setChoices("1");
userAnswerService.save(userAnswer1);
UserAnswer userAnswer2 = new UserAnswer();
userAnswer2.setAppId(2L);
userAnswer2.setUserId(1809119229891362817L);
userAnswer2.setChoices("2");
userAnswerService.save(userAnswer2);
UserAnswer userAnswerServiceOne = userAnswerService.getOne(Wrappers.lambdaQuery(UserAnswer.class).eq(UserAnswer::getAppId, 1L));
System.out.println(JSONUtil.toJsonStr(userAnswerServiceOne));
UserAnswer userAnswerServiceTwo = userAnswerService.getOne(Wrappers.lambdaQuery(UserAnswer.class).eq(UserAnswer::getAppId, 2L));
System.out.println(JSONUtil.toJsonStr(userAnswerServiceTwo));
}
}
系统优化
幂等性设计
需求分析
什么是幂等性?
使用相同参数调用同一接口,调用多次的结果和单次产生的结果是一致的。
用户可能出现误触提交按钮,导致一条信息在数据库出现多次相同的记录,并且调用多次AI,因此需要对接口进行幂等处理
方案选择
1、利用数据库唯一索引保证幂等性
简单说就是由前端调用接口生成提交结果的唯一索引id,我们新增的数据的时候连带id一起插入,如果出现id重复,mysql会报错阻止插入
2、使用乐观锁实现幂等性
大致思路就是给配置表加一个version字段,每次修改之前都要验证版本号和修改前是否一致(不一致说明已经被别人修改),一致才能给版本号+1
3、天然幂等操作
比如delete、update操作,不管执行多少遍,结果都是一样的
4、分布式锁
并发修改的时候,多个线程同时插入。这种情况就可以加分布式锁,让多个线程抢占锁才能执行后续任务
可以选择1、4方案,因为2、3方案不适合插入新数据这种情况
本次选择1方案
后端实现
1、写生成id的接口(雪花算法)
/**
* 为了保证添加项目时的幂等性,不会在数据库添加多条一模一样的数据,
* 前端添加项目的时候,使用后端生成id,id一样就无法重复添加
*/
@GetMapping("/generate/id")
public BaseResponse<Long> generateUserAnswerId() {
// 使用hutool生成雪花id
return ResultUtils.success(IdUtil.getSnowflakeNextId());
}
2、修改用户答题接口
// 保证幂等性
try{
// 写入数据库
boolean result = userAnswerService.save(userAnswer);
ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR);
}catch (DuplicateKeyException e){
// ignore error
log.error("用户答题记录已存在");
}
线程池隔离
需求分析
我们在使用RxJava实现AI题目生成的时候,用到了Schedulers.io()方法,这是个全局共享的线程池,随着业务量级增长,会出现安全隐患!
为什么会出现安全隐患?
如果所有业务公用一个线程池,某个业务出现问题了,占用着线程不放,那其他业务也用不了线程,被阻塞住了,全部一起瘫痪!
因此,一些业务敏感的场景,我们需要隔离线程池
业务优化
假设我们的用户分为VIP用户和普通用户,我们可以设立独立的线程池处理AI题目生成功能,普通的用户使用单线程Schedulers.single()单线程,以此来提高VIP用户的体验感。
后端实现
1、vip配置类
package com.snowyee.yudada.config;
import io.reactivex.Scheduler;
import io.reactivex.schedulers.Schedulers;
import lombok.Data;
import org.jetbrains.annotations.NotNull;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
@Configuration
@Data
public class VipSchedulerConfig {
@Bean
public Scheduler vipScheduler(){
ThreadFactory threadFactory = new ThreadFactory() {
private final AtomicInteger threadNumber = new AtomicInteger(1);
@Override
public Thread newThread(@NotNull Runnable r) {
Thread thread = new Thread(r, "VIPThreadPool-" + threadNumber.getAndIncrement());
thread.setDaemon(false); // 非守护线程
return thread;
}
};
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(10, threadFactory);
return Schedulers.from(scheduledExecutorService);
}
}
2、修改流式生成题目接口
// 默认单线程池,如果是vip就给随机分配线程池
Scheduler scheduler = Schedulers.single();
if (isVip) {
scheduler = vipScheduler;
}
// 截取一道一道的题目进行返回
modelDataFlowable
// 指定观察者的线程池
.observeOn(scheduler)
3、测试效果
模拟普通用户线程阻塞
// 左右括号{}抵消 就返回数据
.doOnNext(c -> {
// 如果是{ , 计数器+1
if (c == '{') {
counter.addAndGet(1);
}
if(counter.get() > 0) {
stringBuilder.append(c);
}
if (c == '}') {
counter.addAndGet(-1);
if (counter.get() == 0) {
// 输出当前线程的名称
System.out.println(Thread.currentThread().getName());
// 模拟普通用户阻塞进程
if (!isVip){
Thread.sleep(10000L);
}
// 拼接题目,并通过SSE返回给前端
sseEmitter.send(JSONUtil.toJsonStr(stringBuilder.toString()));
// 重置,准备下一道题
stringBuilder.setLength(0);
}
}
})
写单元测试看效果
package com.snowyee.yudada;
import com.snowyee.yudada.controller.QuestionController;
import com.snowyee.yudada.model.dto.question.AiGenerateQuestionRequest;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
public class QuestionControllerTest {
@Resource
private QuestionController questionController;
@Test
void aiGenerateQuestionSSETest() throws InterruptedException {
// 模拟调用
AiGenerateQuestionRequest aiGenerateQuestionRequest = new AiGenerateQuestionRequest();
aiGenerateQuestionRequest.setAppId(1813475846485278721L);
aiGenerateQuestionRequest.setQuestionNumber(10);
aiGenerateQuestionRequest.setOptionNumber(2);
// 模拟普通用户
questionController.aiGenerateQuestionSSETest(aiGenerateQuestionRequest,false);
//模拟普通用户
questionController.aiGenerateQuestionSSETest(aiGenerateQuestionRequest,false);
// 模拟会员用户
questionController.aiGenerateQuestionSSETest(aiGenerateQuestionRequest,true);
// 模拟主线程一直启动
Thread.sleep(100000000L);
}
}
结果
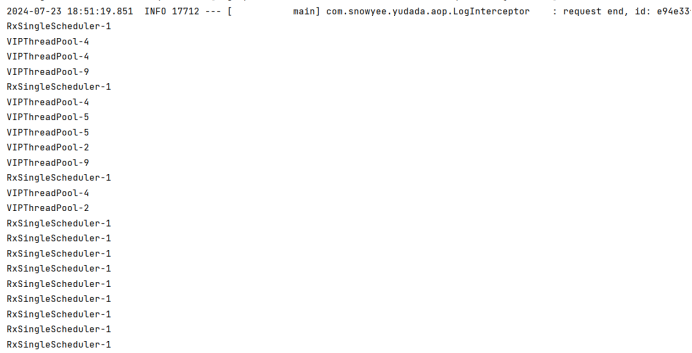
我们可以明显看到普通用户一直使用一个线程,而VIP用户使用的是多线程,很快就处理完了业务。
统计分析
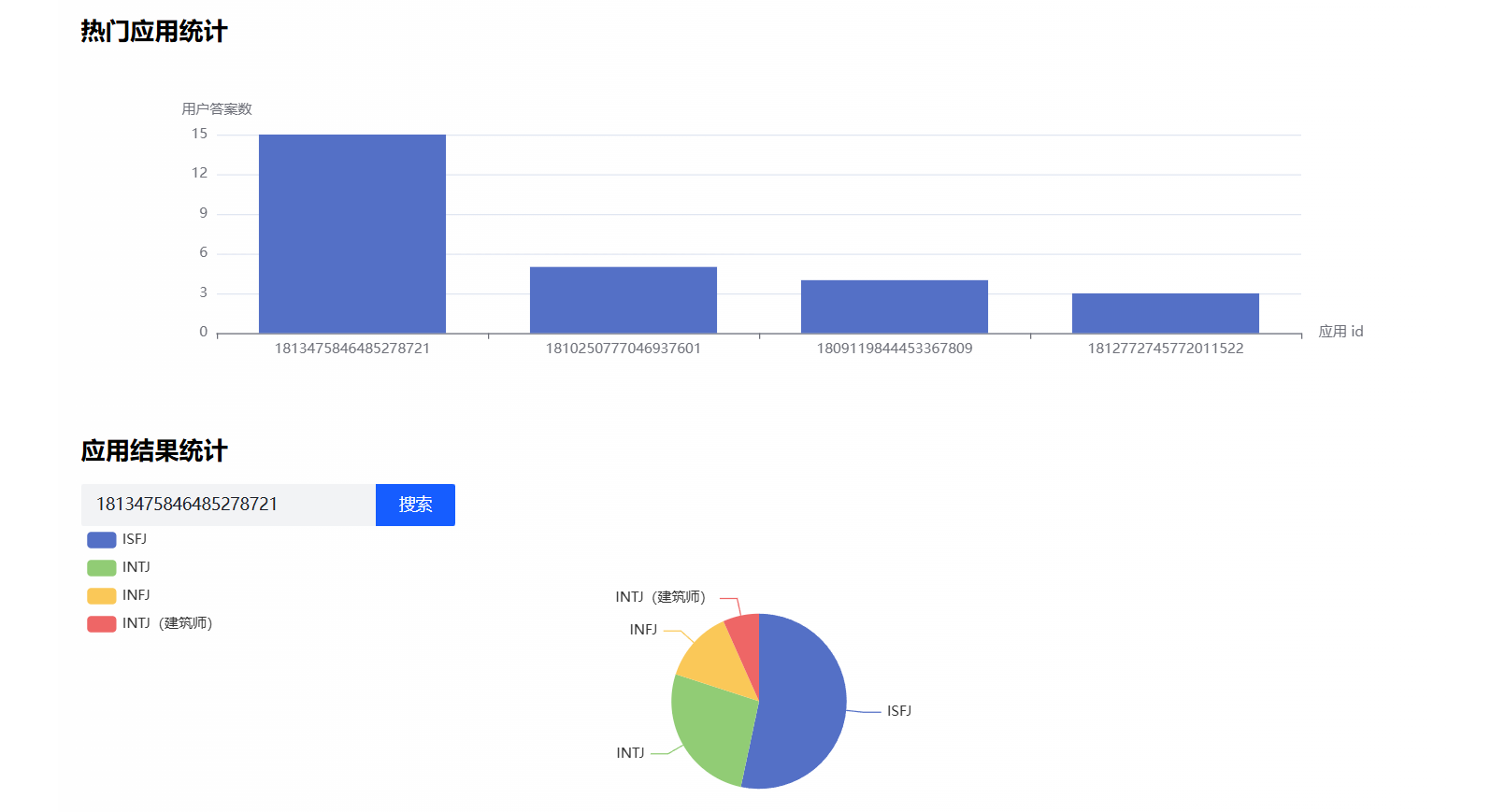
需求分析
为了团队能够有依据的做出更明智的决策,我们需要分析哪个测试用户使用得多,把热门的测试放到靠前的位置。也可以根据用户的答案结果分布,针对群体进行定制化的开发或者投放广告。
方案选择
1、Excel
只适合小规模数据
2、关系型数据库(MySQL、Oracle)
可以做数据规模不大、简单的数据分析
3、第三方数据分析平台
把数据介入到平台内,就可以通过拖拉拽的方式配置图表分析了
相对简单但是要付费
推荐帆软BI、微软Power BI、开源数据分析可以使用Apache Superset
4、大数据分析
需要引入很多组件,做很多基础建设,甚至需要专门的大数据开发人员,成本比较高
大数据分析的基本思路是把要分析的大量数据采集出来,处理成我们需要的格式,存储到数据仓库(HBase、Cassandra),再用一些专业的工具进行数据分析(Spark、Hive),最后接入可视化工具展示(Tableau、Power BI)
后端实现
1、在Mapper里写对应的sql接口,也可以写道xml里,在这里调用
/**
* 记录每个appId下,有多少次回答,一个用户可以有多次回答
* 可以做热门应用排行榜
* @return
*/
@Select("select appId,count(userId) as answerCount from user_answer" +
" group by appId order by answerCount desc limit 10;")
List<AppAnswerCountDTO> doAppAnswerCount();
/**
* 记录每个描述结果下,有多少次回答
* @param appId
* @return
*/
@Select("select resultName,count(resultName) as resultCount from user_answer" +
" where appId = #{appId}" +
" group by resultName order by resultCount desc;")
List<AppAnswerResultCountDTO> doAppAnswerResultCount(Long appId);
2、写controller接口
/**
* App统计分析接口
*
*
*/
@RestController
@RequestMapping("/app/statistic")
@Slf4j
public class AppStatisticController {
@Resource
private UserAnswerMapper userAnswerMapper;
/**
* 统计某个App下用户的答题情况
*/
@GetMapping("/answer_count")
public BaseResponse<List<AppAnswerCountDTO>> getAppAnswerCount(){
return ResultUtils.success(userAnswerMapper.doAppAnswerCount());
}
/**
* 统计某个答案下用户的答题情况
*/
@GetMapping("answer_result_count")
public BaseResponse<List<AppAnswerResultCountDTO>> getAppAnswerResultCount(Long appId){
// 判断一下参数异常
ThrowUtils.throwIf(appId == null || appId <= 0, ErrorCode.PARAMS_ERROR);
return ResultUtils.success(userAnswerMapper.doAppAnswerResultCount(appId));
}
}
其他的实体类略
前端实现
前端数据化展示,可以用echart,为了更方便使用echarts,我们可以用vue-echarts框架
1、引入类库
npm i echarts vue-echarts
2、引入使用组件
<template>
<div id="appStrtisticPage">
<h2>热门应用统计</h2>
<v-chart :option="appAnswerCountOptions" style="height: 300px;"></v-chart>
<h2>应用结果统计</h2>
<div class="searchBar">
<a-input-search
:style="{ width: '320px' }"
placeholder="输入 appId"
button-text="搜索"
size="large"
search-button
@search="(value)=>loadAppAnswerResultCountData(value)"
/>
</div>
<v-chart :option="appAnswerResultCountOptions" style="height: 300px;"></v-chart>
</div>
</template>
<script setup lang="ts">
import { ref, watchEffect, computed } from "vue";
import message from "@arco-design/web-vue/es/message";
import API from "@/api";
import {
getAppAnswerCountUsingGet,
getAppAnswerResultCountUsingGet
} from "@/api/appStatisticController";
// 引入echart
import VChart from "vue-echarts";
import "echarts";
const appAnswerCountList = ref<API.AppAnswerCountDTO[]>([]);
const appAnswerResultCountList = ref<API.AppAnswerResultCountDTO[]>([]);
/**
* 加载数据
* 修改数据的时候重新赋值
*/
const loadAppAnswerCountData = async () => {
const res = await getAppAnswerCountUsingGet();
if (res.data.code === 0) {
appAnswerCountList.value = res.data.data || [];
} else {
message.error("获取数据失败," + res.data.message);
}
};
/**
* 加载数据
* 修改数据的时候重新赋值
*/
const loadAppAnswerResultCountData = async (appId: string) => {
if (!appId) {
return;
}
const res = await getAppAnswerResultCountUsingGet({
appId: appId as any
});
if (res.data.code === 0) {
appAnswerResultCountList.value = res.data.data || [];
} else {
message.error("获取数据失败," + res.data.message);
}
};
// 获取旧数据
watchEffect(() => {
loadAppAnswerCountData();
});
// 获取旧数据
watchEffect(() => {
loadAppAnswerResultCountData("");
});
const appAnswerCountOptions = computed(() => {
return {
xAxis: {
type: 'category',
data: appAnswerCountList.value.map((item) => item.appId),
name: "应用 id"
},
yAxis: {
type: 'value',
name: "用户答案数"
},
series: [
{
type: 'bar',
data: appAnswerCountList.value.map((item) => item.answerCount)
}
]
};
})
const appAnswerResultCountOptions = computed(() => {
return {
tooltip: {
trigger: 'item'
},
legend: {
orient: 'vertical',
left: 'left'
},
series: [
{
name: '应用答案结果分布',
type: 'pie',
radius: '50%',
data: appAnswerResultCountList.value.map((item) => {
return {
value: item.resultCount,
name: item.resultName
}
}),
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
})
</script>
<style scoped></style>
页面效果
主页
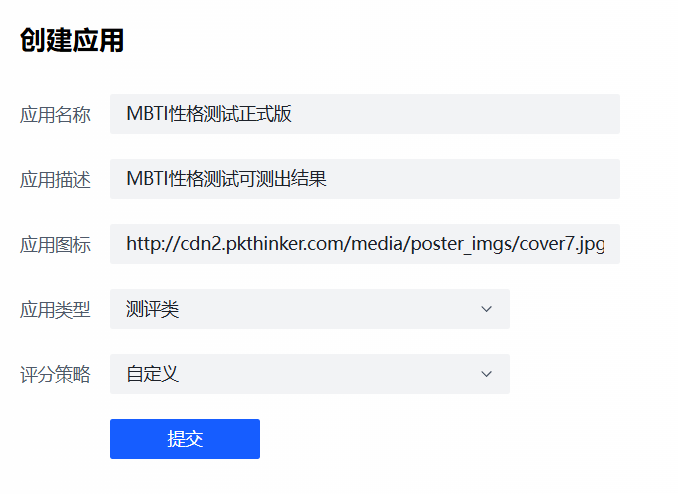
创建应用
设置题目

AI生成题目
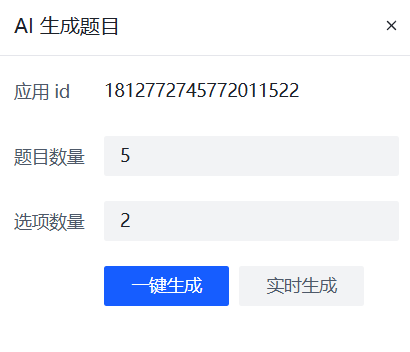
一键生成就是AI生成完题目,设置题目那块直接展示所有题目,实时生成就是AI生成一道题目,左边就展示一道题目
应用分享

设置评分
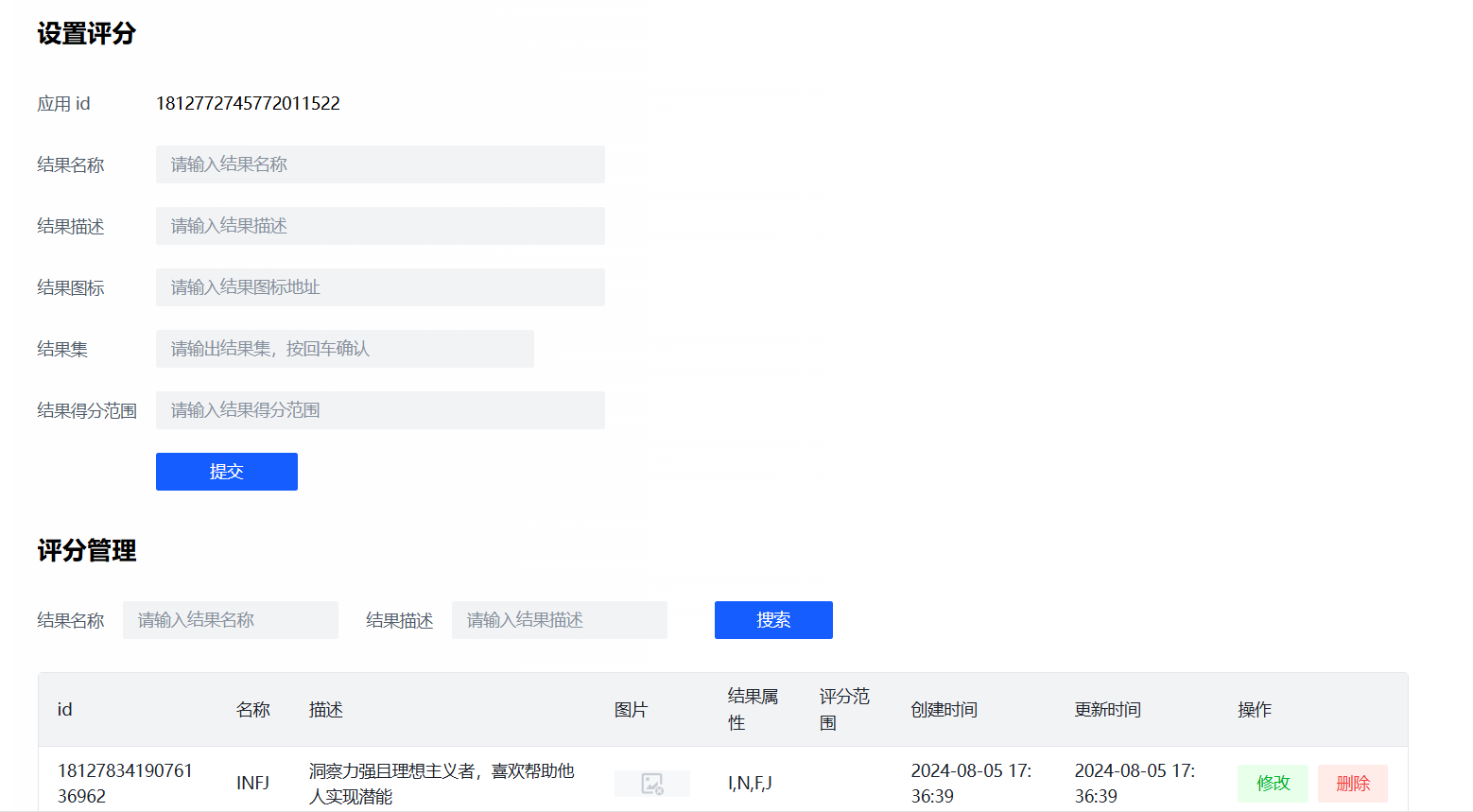
答题页
手动答题结果页
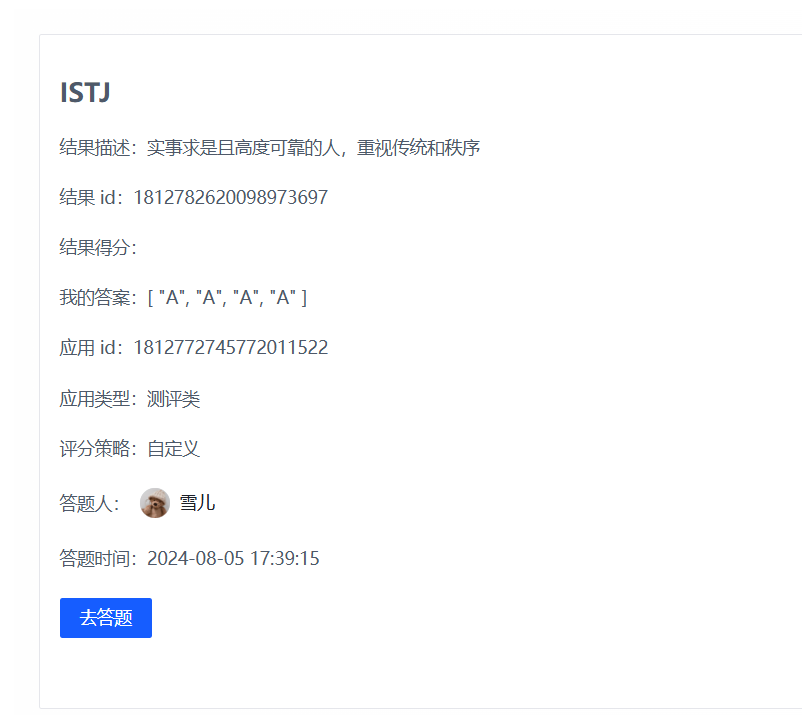
AI答题结果页

管理页面

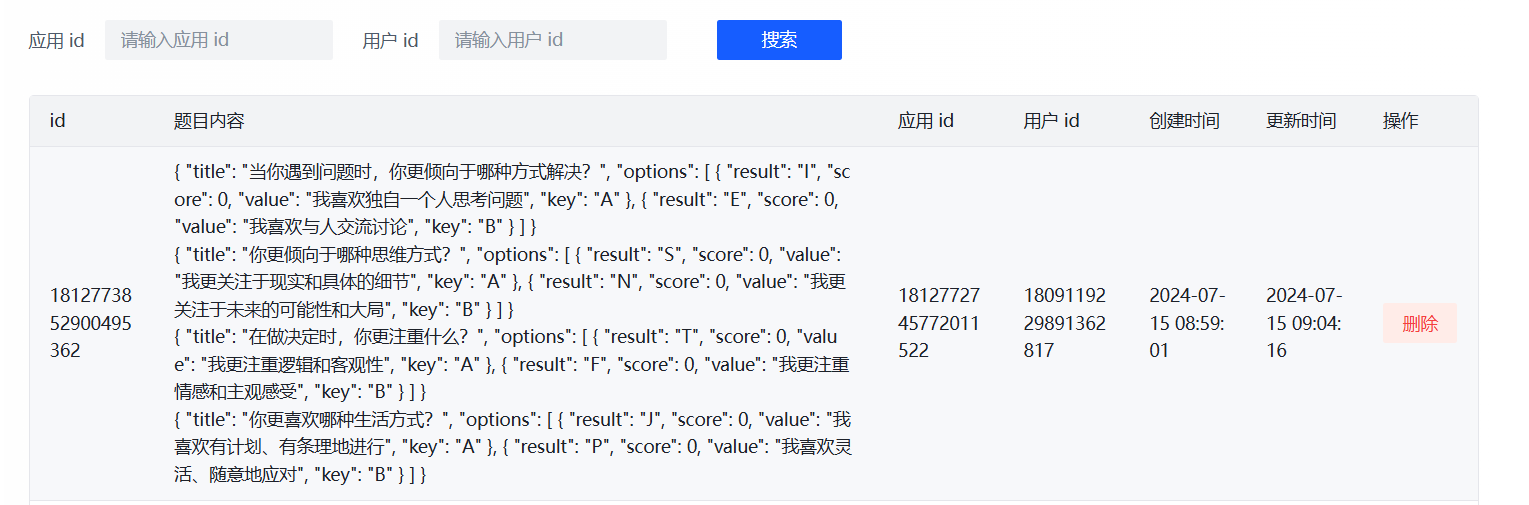
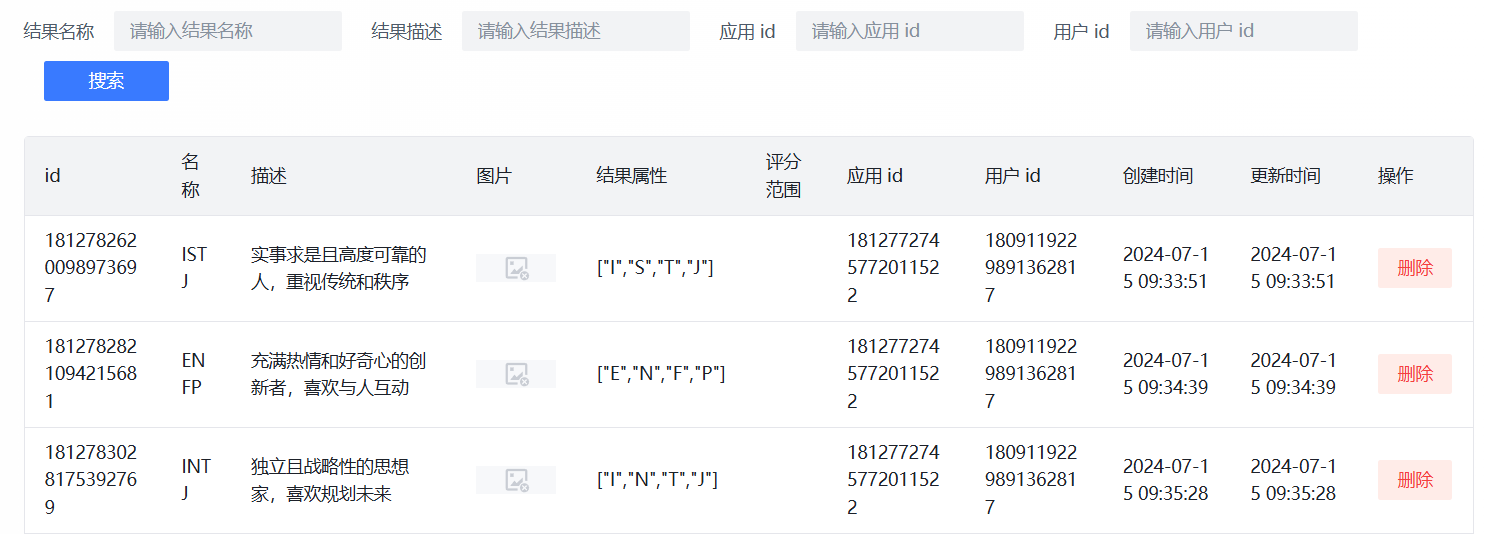
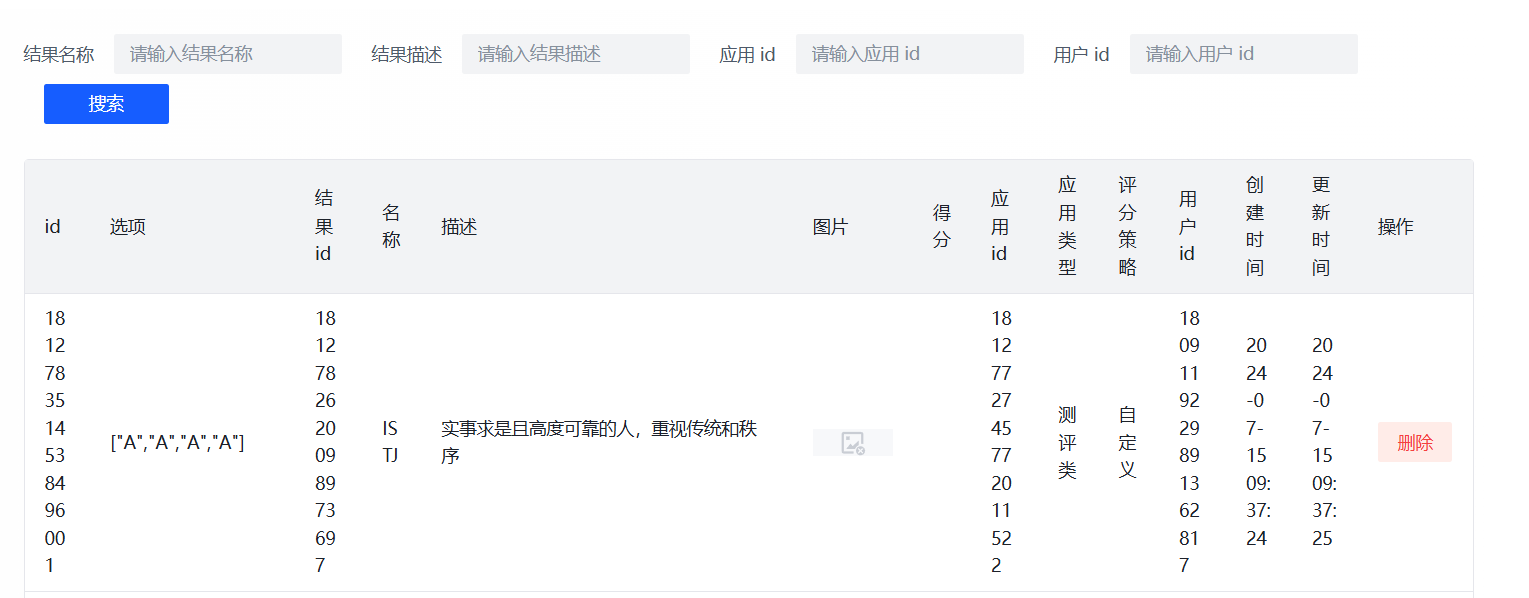
应用统计页面
项目地址
前端地址:https://gitee.com/gu-feiyin/aidada-frontend
后端地址:https://gitee.com/gu-feiyin/yudada-backend
mbti测试小程序地址:https://gitee.com/gu-feiyin/mbti-test-mini